
- 「物体認識」について学びたいけど理解できるか不安・・・
- 「物体認識」の仕組みが分からない?
- 「物体認識」の内容を体系的に教えて!
深層学習を用いた「物体認識」タスクには分類、物体検出、意味領域分割、個体領域分割があり、各々特徴がありますが、その内容が豊富で何から理解したらよいか分からないケースが非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「物体認識」の仕組みやこれまでの流れが分かるよう物体認識の内容について体系的に解説します。
この記事を参考にして「物体認識」の基礎を学べば、E資格に合格できるはずです。
<<物体認識の基礎に関する学習のポイントを今すぐ知りたい方はこちら
鳥瞰図:広義の物体認識タスク
| 難易度 | 目的 | 特徴 | 出力 | ||
|---|---|---|---|---|---|
| 易 | 物体の位置に興味なし | 分類 Classification | (画像に対し単一または複数の) クラスラベル | ||
| ↓ | 個体の区別に興味なし | 物体検出 Object Detection | 画像内の物体を検出し、各々の物体に対して境界Boxを指定 | 物体の位置と種類を特定。 各物体が独立して検出される。 | Bounding Box[bbox/BB] |
| ↓ | 個体の区別に興味なし | 意味領域分割 Semantic Segmentation | 画像内の全てのピクセルを種類に分類 | 同じ種類の物体でも個々に区別せず、全てのピクセルが何らかなの種類に分類される。 | (各ピクセルに対し単一の) クラスラベル |
| ↓ | 統括的領域分割 Panoptic Segmentation | Semantic Segmentationと物体検出の組合せで、画像内の全ての物体を個別に認識し、それぞれのピクセルに種類を割り当てる。 | 個々の物体を識別しつつ、画像内の全ピクセルをカバーする。 | (各ピクセルに対し単一の) クラスラベル | |
| 難 | 個体領域分割 Instance Segmentation | (各ピクセルに対し単一の) クラスラベル |
代表的なデータセット
モデルの性能を適切に評価する
| データセット | クラス | Train+Validation | Box/画像 | 備考 |
|---|---|---|---|---|
| VOC12 | 20 | 11,540 | 2.4 | Instance Annotation |
| ILSVRC17 | 200 | 476,668 | 1.1 | |
| MS COCO18 | 80 | 123,287 | 7.3 | Instance Annotation |
| OICOD18 | 500 | 1,743,042 | 7.0 | Instance Annotation |
小 ←-- Box/画像 --→ 大
アイコン的な映り 部分的な重なり等も
日常感とはかけ 見られる。
離れやすい 日常生活のコンテキスト
に近い
- 【補足】VOC12、ILSVRC17、MS COCO18、OICOD18は物体検出コンペティションで用いられたデータセット
- PASCAL VOC Object Detection Challenge
VOC=Visual Object Classes
主要貢献者が2012年に亡くなったことに伴いコンペも終了 - Ground-Truth BBの情報が、左上隅と右下隅の座標が与えられる
- 画像サイズ:470×380
VOC2007とVOC2012で扱われているクラス数が異なる。
- ILSVRC Object Detection Challenge
ILSVRC=ImageNet Scale Visual Recognition Challenge
コンペは2017年に終了(後継:Open Images Challenge) - ImageNet(21,841クラス/1400万枚以上)のサブセット
Instance Segmentation の学習に必要な情報はない。 - 画像サイズ:500×400
- MS COCO Object Detection Challenge
COCO=Common Object in Context
MS=Microsoft - 物体位置推定に対する新たな評価指標を提案(後述)
- 画像サイズ:640×480
- Opne Images Challenge Object Detection
- ILSVRCやMS COCO とは異なる annotation process
- Open Images V4(6000クラス以上/900万枚以上)のサブセット
画像サイズ:一様ではない
※データセット自体は他にも様々存在:
CIFAR-10/CIFAR-100,Food-101,楽天データ(文字領域アノテーション画像)etc.
代表的データセットのポジショニングマップ
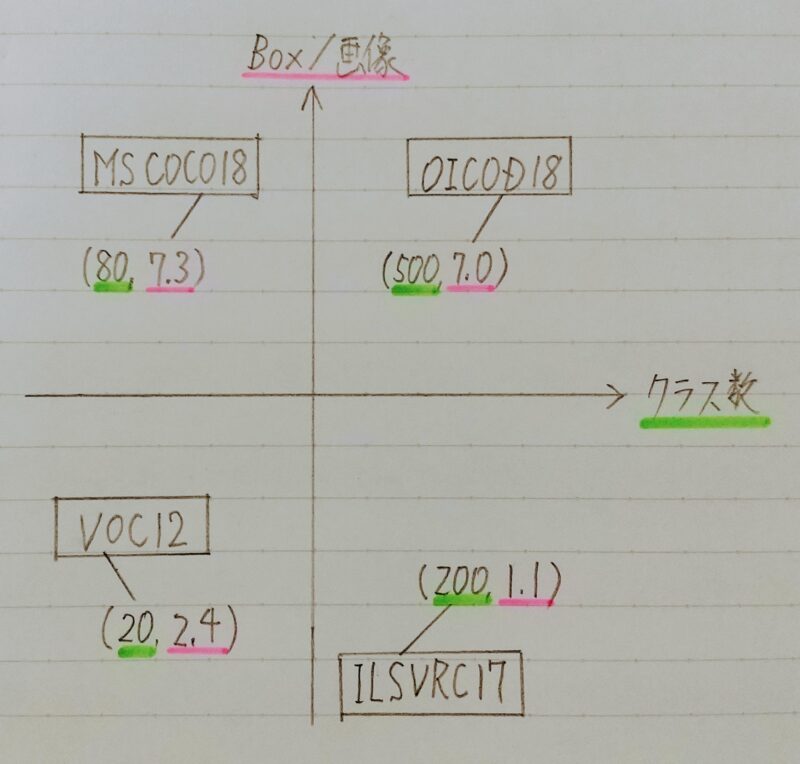
- 目的に応じたBox/画像の選択を!
- クラス数が大きいことはよいことなのか?
フリマアプリの出品画像を入力とする物体検知タスクの開発に取り組みたいけど
どのデータセットを訓練データとして用いると精度を向上できるかな?
フリマアプリの出品画像は物体の位置を正確に検知する必要はないよ!
すなわちBox/画像は少なくていい。
反対に様々な商品を正確に検知する必要があるよ!
すなわちクラス数は多い方がいい。
だから「ILSVRC17」を用いると精度向上が期待できるよ!
評価指標
分類問題における評価指標の復習
| 真値 \予測 | Positive | Negative |
|---|---|---|
| Positive | True Positive | False Negative |
| Negative | False Positive | True Negative |
適合率(Precision):
「Positiveと予測」したものの中で本当に
Positiveである割合
Precision=TP/(TP+FP)
再現率(Recall):
「本当にPositiveなもの」の中からPositiveと
予測できる割合
Recall =TP/(TP+FN)
- confidence(信頼)の閾値を変化させることで「PrecisionーRecall curve」が描ける
閾値変化に対する振る舞い
クラス分類 物体検出
| conf. | pred. | |
|---|---|---|
| S1 | 0.88 | 1 |
| S2 | 0.82 | 1 |
| S3 | 0.71 | 1 |
| S4 | 0.52 | 1 |
| S5 | 0.49 | 0 |
| S6 | 0.44 | 0 |
| conf. | pred. | |
|---|---|---|
| S1 | 0.88 | 1 |
| S2 | 0.82 | 1 |
| S3 | 0.71 | 0 |
| S4 | 0.52 | 0 |
| S5 | 0.49 | 0 |
| S6 | 0.44 | 0 |
| conf | pred. | BB | |
|---|---|---|---|
| P1 | 0.92 | 人 | x1,y1 w1,h1 |
| P2 | 0.85 | 車 | x2,y2 w2,h2 |
| P3 | 0.81 | 車 | x3,y3 w3,h3 |
| P4 | 0.70 | 犬 | x4,y4 w4,h4 |
| P5 | 0.69 | 人 | x5,y5 w5,h5 |
| P6 | 0.54 | 車 | x6,y6 w6,h2 |
| pred. | BB | ||
|---|---|---|---|
| P1 | 0.92 | 人 | x1,y1 w1,h1 |
| P2 | 0.85 | 車 | x2,y2 w2,h2 |
| P3 | 0.81 | 車 | x3,y3 w3,h3 |
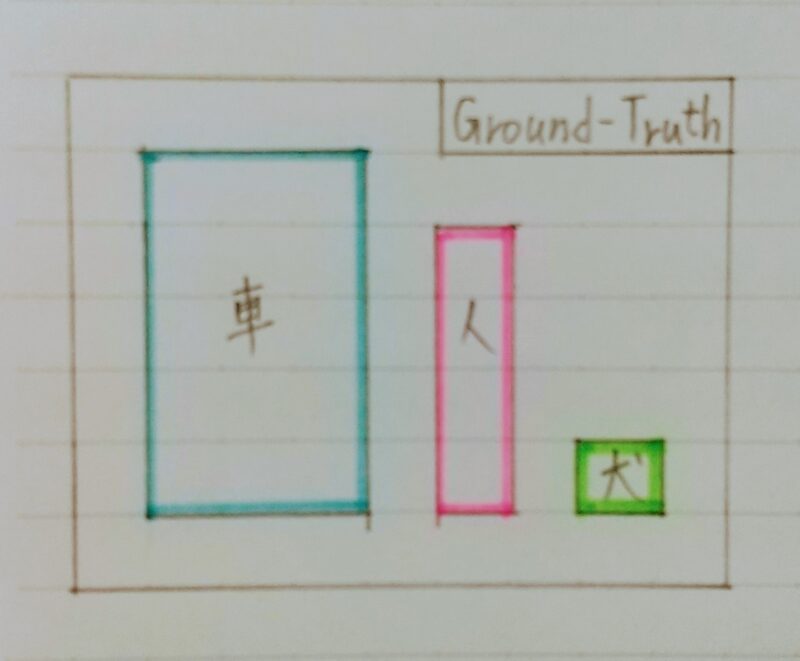
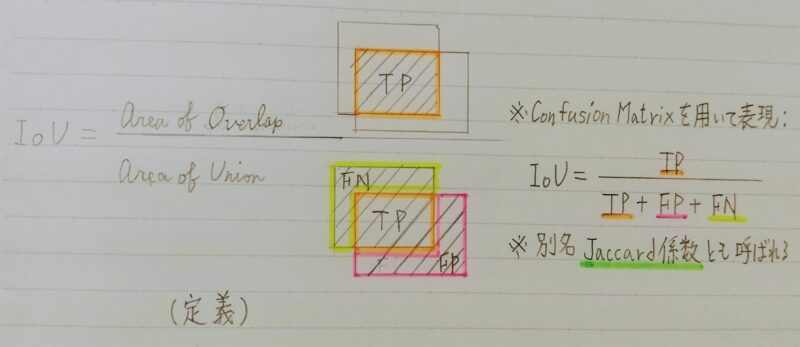
IoU:Intersection over Union
物体検出においてはクラスラベルだけではなく、物体位置の予測精度も評価したい!
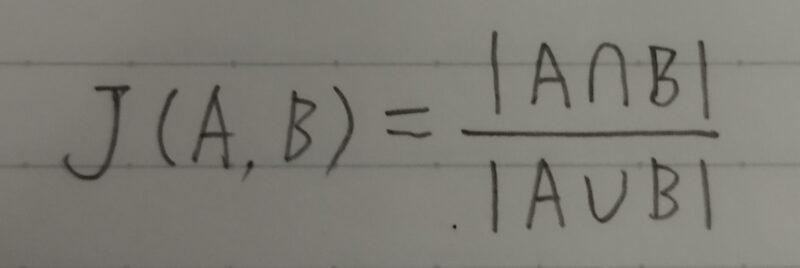
例題
Q1.Predicted BBが完全一致の状態から左方向と下方向に各々1辺の長さの20%だけ平行移動された場合のIoUの値を求めよ。
A1.0.82/(12+12 ー 0.82) ≒ 0.470
入力1枚で見るPrecision/Recall
conf.の閾値:0.5
IoUの閾値:0.5
| conf. | pred. | IoU | |
|---|---|---|---|
| P1 | 0.92 | 人 | 0.88 |
| P2 | 0.85 | 車 | 0.46 |
| P3 | 0.81 | 車 | 0.92 |
| P4 | 0.70 | 犬 | 0.83 |
| P5 | 0.69 | 人 | 0.76 |
| P6 | 0.54 | 車 | 0.20 |
→Conf.>0.5の予測群
→ IoU>0.5よりTP(人を検出)
→ IoU<0.5よりFP
→ IoU>0.5よりTP(車を検出)
→ IoU>0.5よりTP(犬を検出)
→ IoU>0.5であるが既に検出済みなのでFP
→ IoU<0.5よりFP
Precision:
3 /(3+3)=0.50
Recall:
3 /(3+0)= 1.00
Precision/Recallの計算例(クラス単位)
| Pic. | conf. | pred. | IoU | |
|---|---|---|---|---|
| P1 | 1 | 0.92 | 人 | 0.88 |
| P2 | 2 | 0.85 | 人 | 0.46 |
| P3 | 2 | 0.81 | 人 | 0.92 |
| P4 | 3 | 0.70 | 人 | 0.83 |
| P5 | 1 | 0.69 | 人 | 0.76 |
| P6 | 3 | 0.54 | 人 | 0.20 |
conf.の閾値:0.5
ー--ー-→
IoUの閾値:0.5
| TP/FP | |
|---|---|
| P1 | TP |
| P2 | FP |
| P3 | TP |
| P4 | TP |
| P5 | FP |
| P6 | FP |
Precision:
3/(3+3)=0.5
#All Predictions
Recall:
3/(3+1)=0.75
#All Ground-Truth
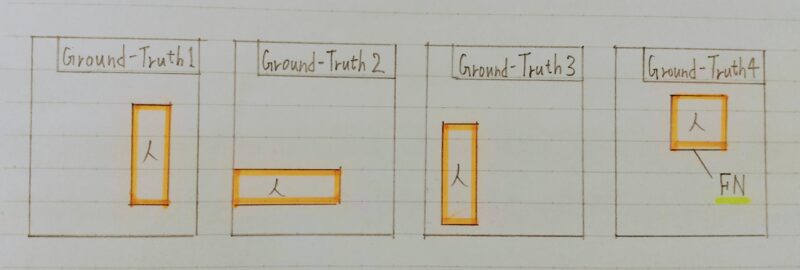
AP:Average Precision
クラスラベルを固定
| conf. の閾値 | IoU の閾値 | Precision | Recall |
|---|---|---|---|
| 0.05 | 0.5 | ||
| 0.1 | 0.5 | ||
| ・ ・ ・ | ・ ・ ・ | ・ ・ ・ | ・ ・ ・ |
| 1.00 | 0.5 |
conf.の閾値をβとするとき、
Recall = R(β)、Precision=P(β)
ー---→ P=F(R) [PrecisionーRecall curve]

※厳密には各Recallのレベルに対して最大のPrecisionに
スムージング
※積分はInterpolated APとして有限点(e.g.,11点)で計算される
「任意の Predicted BB に検出されないGroundーTruth BB」 の扱い ⇒ False Negative
mAP:mean Average Precision
- Average Precisionの定義
・・・・・・・・クラスラベル固定のもとで考えていたことに注意(APはクラスごとに計算される)
(算術平均):クラス数がCのとき、
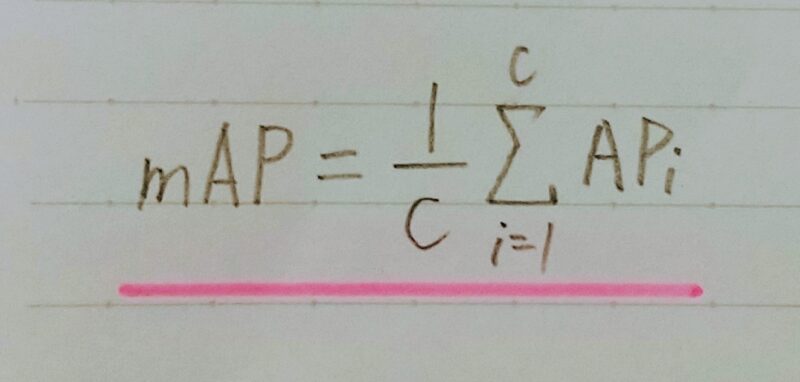
| 車 | 人 | 犬 | |
|---|---|---|---|
| AP | 86.4 | 67.2 | 64.3 |
| mAP | 約72.6 |
- BB位置の精度を重視した指標
- ここまで、IoU閾値は0.5で固定
→0.5から0.95まで0.05刻みでAP&mAPを計算し算術平均を計算

FPS:Flames per Second
【物体検知】 応用上の要請から、検出精度に加え検出速度も問題となる
物体検出の大枠
画期的な出来事:深層学習以降の物体検出
- 2012 AlexNetの登場を皮切りに、時代はSIFTからDCNNへ
補足)SHIFT:Scale Invariant Feature Transform
DCNN:Deep Convolutional Neural Network
深層学習以前の物体検知にも興味のある方への参考文献
Lowe D.(1999)
“Object recognition from local scale invariant features“
AlexNetの原論文を読んだことのない人へ
Krizhevsky A. et ai.(2012)
“ImageNet classification with deep convolutional neural networks“
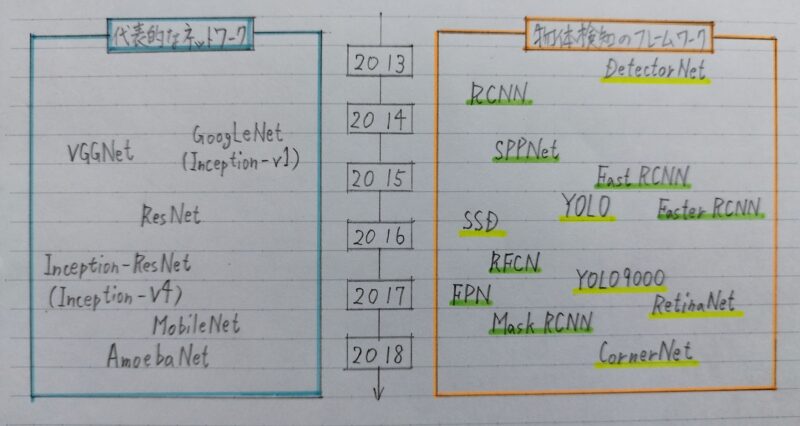
物体検出のフレームワーク
2段階検出器(Twoーstage detector)
・候補領域の出力とクラス推定を別々に行う
・相対的に精度が高い傾向
・相対的に計算量が大きく推論も遅い傾向
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
1段階検出器(Oneーstage detector)
・候補領域の出力とクラス推定を同時に行う
・相対的に精度が低い傾向
・相対的に計算量が小さく推論も早い傾向

まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント