
- 「双方向RNN」について学びたいけど理解できるか不安・・・
- 「双方向RNN」についてどこから学んでいいか分からない?
- 「双方向RNN」のポイントを教えて!
「双方向RNN(Bidirectional Recurrent Neural Network)」は、過去の情報だけではなく、未来の情報を加味することで、精度を向上させるためのモデルですが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「双方向RNN」のポイントについて解説します。
この記事を参考に「双方向RNN」が理解できれば、E資格に合格できるはずです。
目次
双方向RNN
双方向RNN(Bidirectional Recurrent Neural Network)とは・・・
- 従来のRNN(Recurrent Neural Network:再帰型ニューラルネットワーク)のように過去の情報だけではなく、未来の情報を加味することで、精度を向上させるためのモデル
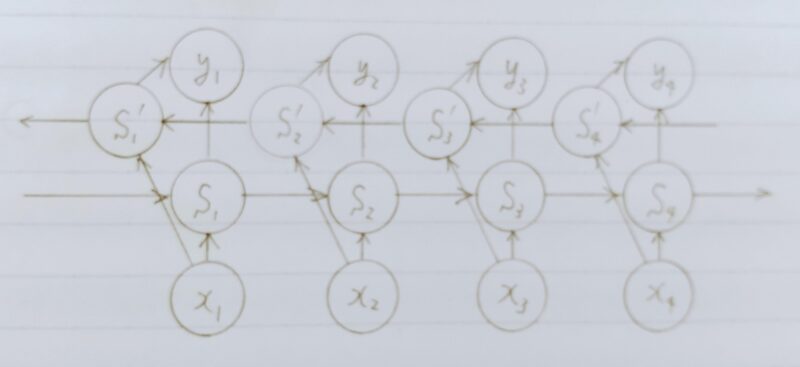
- 実用例
文章の推敲(すいこう)や、機械翻訳等
補足)推敲・・・詩や文章の表現などを見直し、修正を加え練り上げるという意味
確認テスト
問題1
- Q1.以下は双方向RNNの順伝播を行うプログラムである。順方向については、入力から中間層への重みW_f、1ステップ前の中間層出力から中間層への重みをU_f、逆方向に関しては同様にパラメータW_b,U_bを持ち、両者の中間層表現を合わせた特徴から出力層への重みはVである。_rnn関数はRNNの順伝播を表し中間層の系列を返す関数であるとする。(か)にあてはまるのはどれか。
def bidirectional_rnn_net(xs, W\f, U_f, W_b, U_b, V):
”””
W_f, U_f: forward rnn weights, (hidden_size, input_size)
W_b, U_b: backward rnn weights, (hidden_size, input_size)
V: output weights, (output_size, 2*hidden_size)
”””
xs_f = np.zeros_like(xs)
xs_b = np.zeros_like(xs)
for i, x in enumerate(xs):
xs_f[i] = x
xs_b[i] = x[::-1]
hs_f = _rnn(xs_f, W_f, U_f)
hs_b = _rnn(xs_b, W_b, U_b)
hs = [ (か) for h_f, h_b in zip(hs_f, hs_b)]
ys = hs.dot(V.T)
return ys - A1.np.concatenate([h_f, h_b[::-1]], axis=1)
補足1)concatenate(〇,〇,axis=〇)・・・文字列を結合する
補足2)
concatenate(○○〇, axis=0) の場合
[○,○,・・・,〇] [△,△,・・・,△]
↓
[〇,〇,・・・,〇,△,△,・・・,△]
concatenate(○○〇, axis=1) の場合
[○,○,・・・,〇] [△,△,・・・,△]
↓
[[○,△]
[○,△]
・
・
・
[○,△]]
問題2
- Q2.RNNや深いモデルでは勾配消失または爆発が起こる傾向がある。勾配爆発を防ぐために勾配のクリッピングを行うという手法がある。具体的には勾配のノルムが閾(しきい)値を超えたら、勾配のノルムを閾値に正規化するというものである。以下は勾配のクリッピングを行う関数である。(さ)にあてはまるのはどれか。
def gradient_clipping(grad, threshold):
”””
grad: gradient
”””
norm = np.linalg.norm(grad)
rate = threshold / norm
if rate < 1:
return (さ)
return grad - 補足)threshold・・・閾(しきい)値
- A2. (1) gradient*rate
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント