
- 「GAN(敵対的生成ネットワーク)」について学びたいけど理解できるか不安・・・
- 「GAN(敵対的生成ネットワーク)」についてどこから学んでいいか分からない?
- 「GAN(敵対的生成ネットワーク)」を体系的に教えて!
「GAN(Generative Adversarial Networks:敵対的生成ネットワーク)」は、生成器と識別器を競わせて学習する生成モデルであり非常に面白い技術ですが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこで、この記事では「GAN」のポイントについて解説します。
この記事を参考に「GAN」が理解できれば、E資格に合格できるはずです。
GANの構造
- 生成器(Generator)と識別器(Discriminator)を競わせて学習する生成モデル
生成器(Generator):乱数からデータを生成
識別機(Discriminator):入力データが真データ(学習データ)であるかを識別 - 潜在的因子を再構成するためのアプローチ
「潜在的因子」の意味がよく分からない?
「潜在的因子」とは・・・
観測データの中にあるものだよ!!
表現学習において得られた表現の特徴量と対応しているものです。
(表現学習における理想的な表現の仮説の1つ)
「表現学習」の意味がよく分からないわ?
「表現学習」とは・・・
機械学習のタスクの実行に有用な特徴表現を学ぶ手法のことだよ!!
具体的には画像、音、自然言語、時系列データなどの高次元なデータを、予測タスクを解くことで低次元な特徴表現に変換することです。
難しい言葉が沢山出てくるけど焦らず、一つずつ理解していこう!!
引用元:Qiita
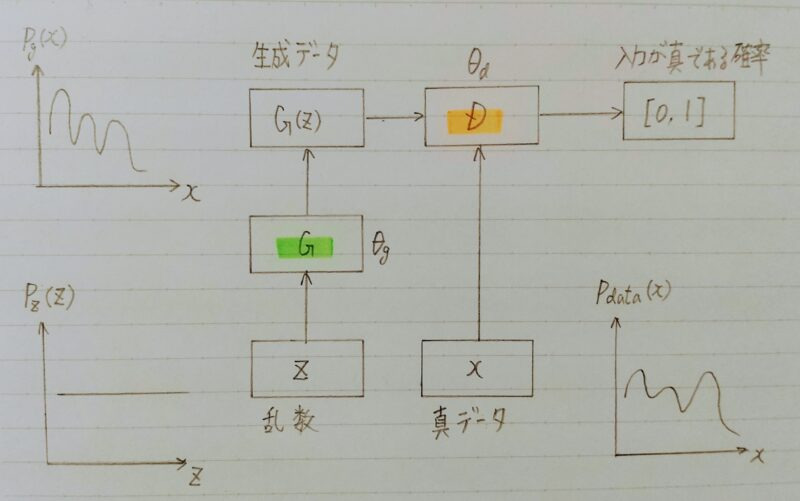
- D(Discriminator:識別器):Gが生成するデータを正しく判別したい
- G(Generator:生成器):Dに誤判断させたい
↓
DとGの2プレイヤーのミニマックスゲーム
ミニマックスゲーム
- 1人が自分の勝利する確率を最大化する作戦を取る
- もう1人は相手が勝利する確率を最小化する作戦を取る
- GANでは価値関数Vを大きくする
→D(自分)が最大化
→G(相手)が最小化
GANの価値関数は以下のとおり。
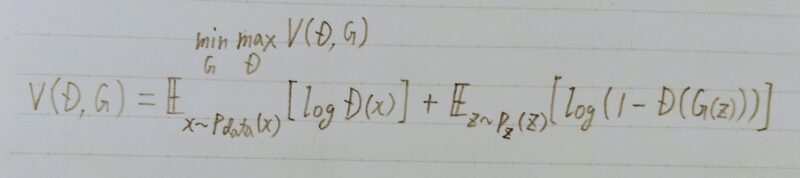
以下、GANの価値関数を導出する。
GANの価値関数は binary cross entropy(バイナリークロスエントロピー)と似ている
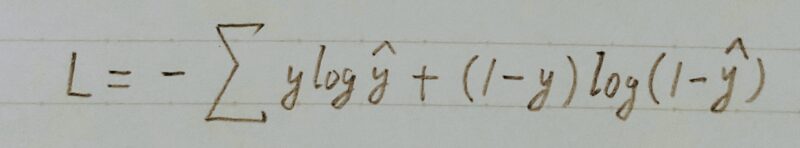
- 単一データのbinary cross entropy(バイナリークロスエントロピー)
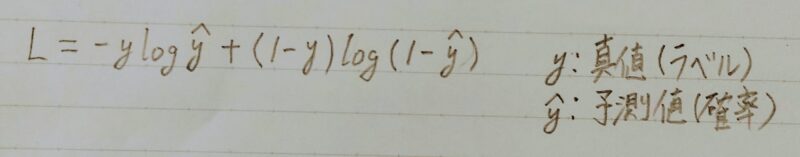
- 上式(=単一データのバイナリークロスエントロピーの数式)において真データを扱う時:
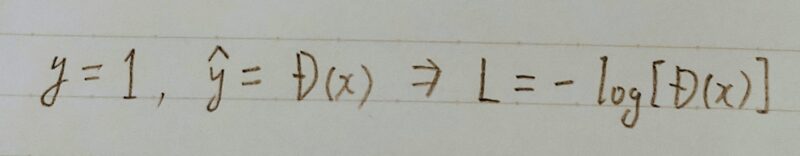
- 上式(=単一データのバイナリークロスエントロピーの数式)において生成データを扱う時:
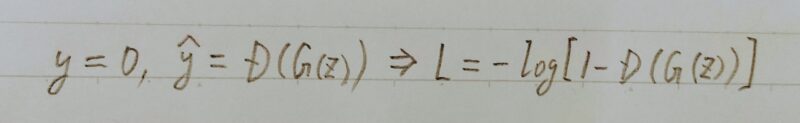
- 上記2つの式を足し合わせる
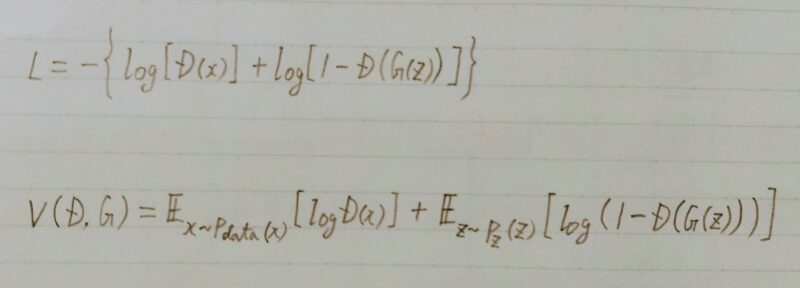
- 複数データを扱うために期待値を取る
- 期待値:何度も試行する際の平均的な結果値 Σxp(x)
価値関数の最適化方法
- Generatorのパラメータθgを固定
■真データと生成データをm個ずつサンプル
■θdを勾配上昇法(Gradient Ascent)で更新 ←θdをk回更新
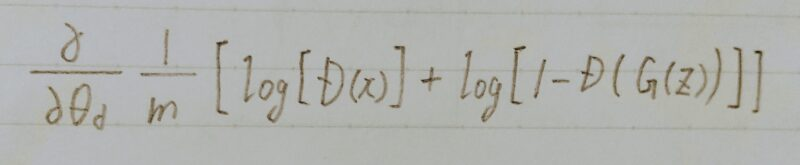
- Discriminatorのパラメータθdを固定
■生成データをm個ずつサンプル
■θgを勾配降下法(Gradient Descent)で更新 ←θgを1回更新
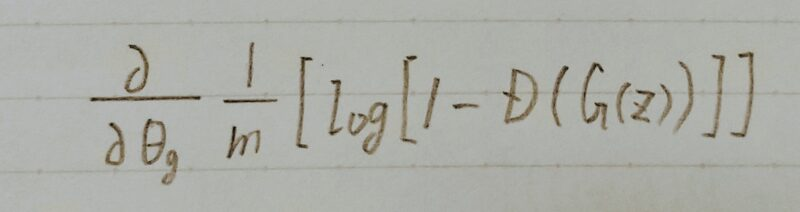
- なぜGeneratorは本物のようなデータを生成するのか?
生成データが本物とそっくりな状況とは?
■pg=Pdata であるはず
- 価値関数がPg=Pdata の時に最適化されていることを示せばよい
最適化方法の具体的ステップ
次の2つのステップにより確認する
- Gを固定し、価値関数が最大値を取るときのD(x)を算出
- 上記のD(x)を価値関数に代入し、Gが価値関数を最小化する条件を算出
- Generatorを固定
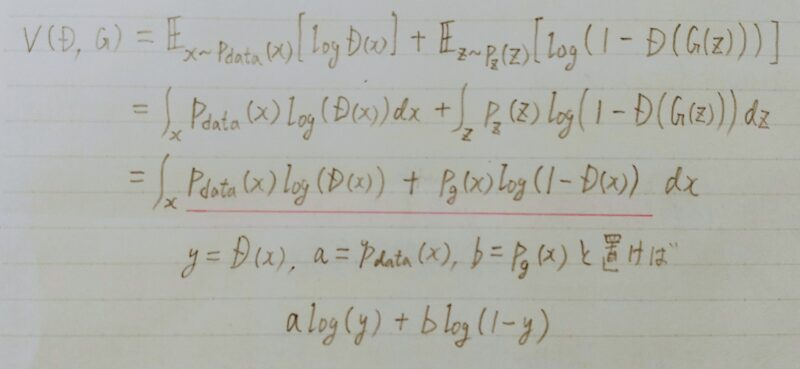
- a log(y)+b log(1ーy)の極値を求めよう
- a log(y)+b log(1ーy)をyで微分
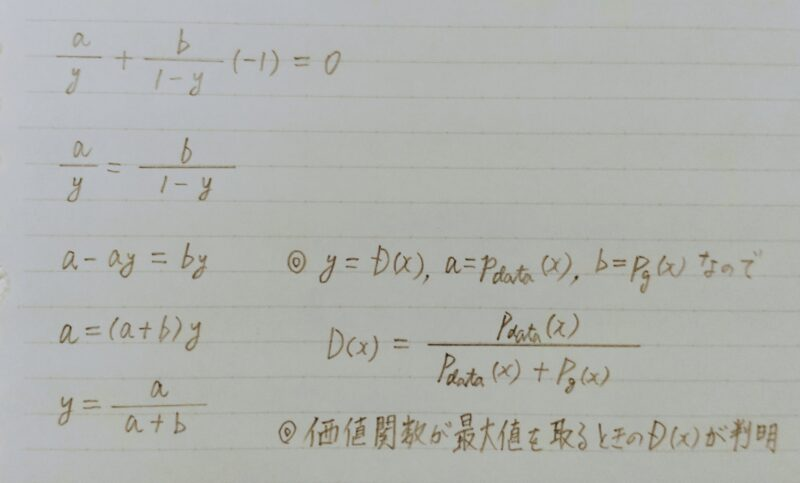
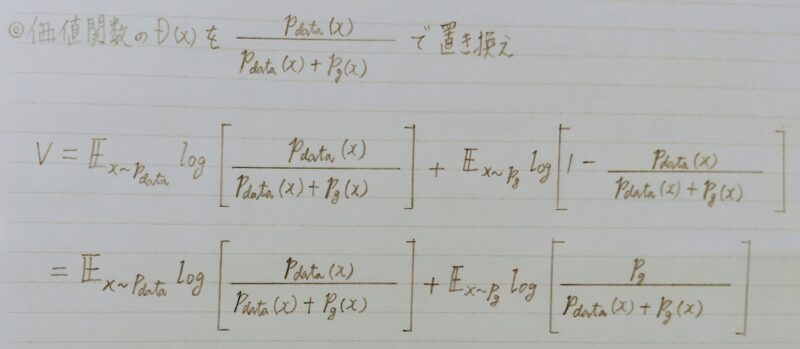
Pg:生成するデータ分布
pdata:真のデータの分布
- 二つの確率分布がどれぐらい近いのか調べる必要がある
■有名な指標としてJSダイバージェンスがある。
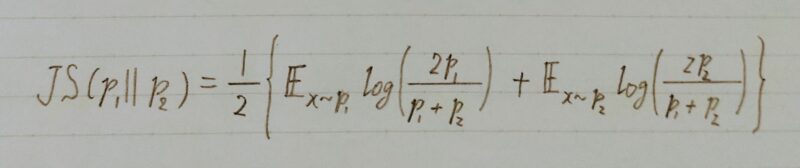
KLーダイバージェンスの式は二つの確率分布の順番を入れ替えると式の値が変わるため、JSーダイバージェンスの式が用いれらることがある。JSダイバージェンスは非負で、分布が一致する時のみ0の値を取る。
JSーダイバージェンスは二つの確率分布を入れ替えても対称性が成り立つ。
引用元:「VasteeLab」
ステップ2:価値関数はいつ最小化するか?
- 価値関数を変形

- GANの学習によりGは本物のようなデータを生成できる。
学習が進み、理想的な状況の下で生成器と識別器の損失関数が収束し、最適な生成器と識別器の両方が得られた場合、識別器Dの出力D(x)はいくらになるかな?
生成器Gと生成するデータ分布pgと真のデータの分布pdataが一致するため、識別器Dの出力D(x)は0.5になるよ!
- 生成器の出力層:tanh
- 出力層以外の各層:ReLU
- 識別器の全層:Leaky ReLU
Discriminatorの更新よりもGeneratorの更新の方が勾配消失問題が起きやすい
(Generatorの出力がDiscriminatorに入力されるため)
DCGAN(Deep Convolutional GAN)
- GANを利用した画像生成モデル
- 下記の構造制約により生成品質を向上
- Generator
・Pooling層の代わりに転置畳み込み層(transposed convolution)を使用 ← Pooling処理をすると画像が荒くなるため
・活性化関数(最終層):tanh関数
・活性化関数(最終層以外):ReLU関数 - Discriminator
・Pooling層の代わりに畳み込み層を使用 ← Pooling処理をすると画像が荒くなるため
・活性化関数(最終層):シグモイド関数
・活性化関数(最終層以外):Leaky ReLU関数
Leaky ReLU関数は負の入力 ⇒ 微小な負の値を出力 - 共通事項
・中間層に全結合層を使わない
・Batch正規化(Batch normalization)を適用 ← 勾配消失問題を回避
- Fast Biーlayer Neural Synthesis of One-Shot Realistic Head Avatars
- 1枚の顔画像から動画像(Avatar)を高速に生成するモデル
- 初期化部と推論部から成る
・初期化:人物の特徴を抽出、1アバターにつき1回の計算コスト
・推論:所望の動きを付ける、時間フレーム分だけの計算コスト - 計算コストの比較
・従来:初期化の計算コストが小さく、推論部の計算コストが大きい
・提案:初期化の計算コストが大きく、推論部の計算コストが小さい
↑リアルタイムで推論できる
- 緻密な輪郭と粗い顔画像を別々に生成し結合する
・初期化時に輪郭情報を生成(ポーズに非依存)
・推論時に粗い動画像を生成(ポーズに依存)
・輪郭画像と低周波動画像を別々に生成する
その他のGAN
- LAPGAN
- ACGAN
- SNGAN
- ラプラシアン ピラミッドを使用した深い生成画像モデル
- CNN(畳み込みニューラルネットワーク)を使ったモデルで、低解像度の画像を学習し、徐々に高解像度の画像を学習するような多段構造のネットワークを作成
→ 高解像度の画像を作成することに成功 - 初めは画像を生成するモデルとして発案
→ 近年は動画や音楽などのタスクにも応用
- Auxiliary Classifier Generative Adversarial Network
- Generatorに「入力ノイズとしてのベクトル+入力画像のクラス情報」を同時に与える
- Discriminatorが生成画像の真偽の判別を行う。
- 新しい正規化の手法を提案 → Spectral Normalization
Spectral Normalization・・・GANの安定化手法。Spectral NormではDiscriminatorのBatch NormをSpectral Normという特別なNormalizationレイヤーに置き換えるということで、この制約を実現している。
引用元:「Qiita」
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント