
- 「GPT(自然言語処理)」について学びたいけど理解できるか不安・・・
- 「GPT(自然言語処理)」のメリットが分からない
- 「GPT(自然言語処理)」を体系的に教えて!
GPT(Generative PreーTraining)は自然言語処理において代表的な事前学習モデルで、最近、話題のChatGPT(人間のように自然な会話ができるAIチャットサービス)もこの派生モデルになります。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格ししました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「GPT」を理解するための3つのポイント解説します。
この記事を参考に「GPT」が理解できれば、E資格に合格できるはずです。
目次
GPTーn-モデルー事前学習と転移学習
GPT-n以前の自然言語処理モデルの課題
ラベル付けされたテキストデータが必要であるため、大量のデータを用意するのが困難
↓
GPT-1の工夫
↓
GPTにおける事前学習
- 巨大な文章のデータセット(コーパス)を用いて事前学習(pre-trained)
→ 汎用的な特徴量を習得済みで、転移学習(transfer learning)に使用可能 - 転移学習を活用すれば、手元にある新しいタスク(翻訳や質問応答など)に特化したデータセットの規模が小さくても、高精度な予測モデルを実現できる
- 転用する際にはネットワーク(主に下流)のファインチューニングを行う
代表的な事前学習モデル
- 代表的な事前学習モデル:
BERT 、GPT-n があり、特徴は事前学習と転移学習において全く同じモデルを使う - 汎用的な学習済み自然言語モデルは、オープンソースとして利用可能なものもある
- GPT-3原論文:「Language Models are Few-Shot Learners」
引用元:https://arxiv.org/abs/2005.14165
GPT-nモデルの特徴
GPT(Generative PreーTraining)とは・・・
- 2019年にOpenAIが開発した有名な事前学習モデル
その後、GPT-2、GPT-3が相次いで発表 - パラメータ数が桁違いに増加
特に、GPTー3のパラメータ数は1750億個にもなり、約45TBのコーパスで事前学習をおこなう。 - 2022年11月にChatGPTが公開される。ChatGPTは人間のように自然な会話ができるAIチャットサービス。
- 2023年3月にGPT-4がリリースされた。GPT-3に比べて出力精度が向上した。
GPTの仕組み
GPTの仕組み
- ①構造はTransfomerを基本
「ある単語の次に来る単語」を予測し、自動的に文章を完成できる ⇒ 「教師なし学習」を行う。 - ②出力値:その単語が次に来る確率
例えば、単語系列 “After”、”running”、”I”、”am” の次に来る単語の確率が、”tired”.40%、”hot”.30%、”thirsty”.20%、”angry”.5%、”empty”.5%になったと仮定すると、”tired”や”hot”の可能性が高い、”angry”や”empty”は低い。 - ③学習前の1750億個のパラメータはランダムな値に設定され、学習を実行後に更新される。学習の途中で誤って予測をした場合、誤りと正解の間の誤差を計算しその誤差を学習する。
GPT-3について報告されている問題点
GPT-3について報告されている問題点
- 社会の安全に関する課題
・「人間らしい」文章を生成する能力を持つために、フェイクニュースなどの悪用のリスクがある。
・現在は完全オープンソースとして提供されておらず、OpenAIへAPの利用申請が必要 - 学習や運用のコストの制約
・膨大な数のパラメータを使用したGPT-3の事前学習を現実的な時間で実現するためには、非常に高性能なGPUを必要とする - 機能の限界(人間社会の慣習や常識を認識できないことに起因)
・生成した文章の文法が正しくても、違和感や矛盾を感じることがある
・「物理現象に関する推論」が苦手(例:「アイスを冷凍庫に入れると硬くなりますか」には答えにくい)
GPTの事前学習
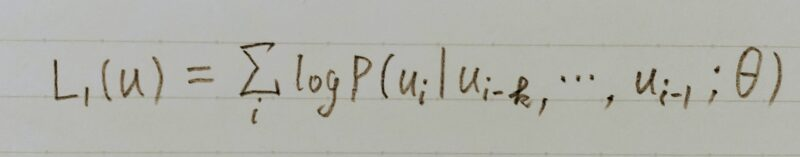
- 事前学習では、この式を最大化するように学習する
- u={u1,・・・,un}が言語データセット(ラベルなし)で、{}の中はそのデータ
セットの一つ一つの単語を示している
- k がコンテキストウィンドウといって単語 ui を予測するためにその前の単語を
何個使うのかを示しているθがニューラルネットワークのパラメーター

- 学習の流れを表している
- U={uーk,・・・,u-1}が、先程出てきた、対象の単語を予測するために使う複数の単語
- We が単語の埋め込み表現、Wp が位置エンコーディングベクトル
- h0は単語の埋め込み表現に位置エンコーディングを足したもの
- transformer_block は transformer の decoder を使う
- nがtransformerのレイヤーの数を表していて、h0を入力として入れ、その出力のh1を次のレイヤーの入力として入れ次のレイヤーにh2を…という操作をn回行う
- transformerの出力と埋め込み表現の転置行列をかけたものをsoftmax関数に入れ、最終的な出力とする。
GPT-1 の fine-tuning
- 転移学習では、始まりを表す記号、文と文を区切る記号、終わりを表す記号を使う
- テキスト分類では区切りの記号は使わず、テキストのTransformerを入れ、線形結合、softmaxに通し答えを得る
- 文同士の関係を予測する場合は区切り記号を使って予測する
- 分の類似度を予測する場合は、二つの文を区切り文字で区切り、順番を入れ替えた入力をもう一つ用意する
- それぞれTransformerに入力し、その出力を足して線形結合ー>softmax で類似度を得る
- 複数の文から一つを選ぶ場合、線形結合層もそれぞれ分かれていて、それぞれの出力を比較して最終的な答えとする
- GPT-2、GPT-3でも細かい変更はあるものの基本的なモデルの構造は変わらない
GPT-2での変更点
- Layer Norm の位置を前にずらしたこと
- 最後のself-attentionブロックの後にもLayer Norm層を入れたこと
- GPT-2のその他の変更点:
バッチサイズやデータセットを大きくした - GPT-3のその他の変更点:
埋め込みサイズ、層、Multi-Head Attentionの数、コンテキストウィンドウの数を増やした
GPTー3とは
GPTー3の特徴
- 改めて勾配を更新し直すことをしない。
- 推論は、Zero-Shot、One-Shot、Few-Shotに分類できる。
・Zero-Shot:何のタスクか(翻訳なのか、文生成なのかなど)を指定した後、すぐ推論させる
・One-Shot:何のタスクかを指定した後、1つだけラベル付きの例を教え、その後推論させる。⇒ fine-tuningを必要としない
・Few-Shot:何のタスクかを指定した後、2つ以上の例を教え、その後推論する。
GPTの性能
GPTの特徴
GPTの長所
- 幅広い言語タスクを高精度で実現できる
- あたかも人間が書いたような文章を生成できて、翻訳、質疑応答、文章の穴埋め、ソースコード生成など、様々なアプリケーションに使用できる
GPTの性能
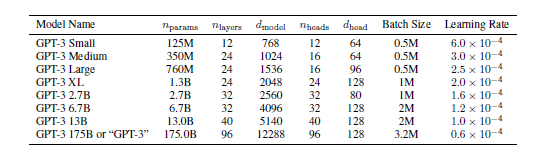
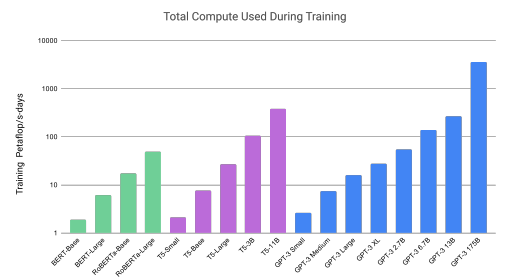
- 以下はGPTの性能を示した表とグラフである。
引用元:https://arxiv.org/abs/2005.14165
GPT-3のモデルサイズを大きくすると、訓練に要する計算量が増加する。
BERTとGPTの比較
| GPT | BERT | |
|---|---|---|
| Transformer | ・デコーダー部分を使用 ・単一方向 | ・エンコーダー部分を使用 ・双方向 |
| fine-tuning | 不要 | 必要 |
| 特徴 | 常に次の単語を予測するため、双方向ではない | 文の中のどの位置の単語もマスクされる可能性があり、マスクした前の単語も後ろの単語にも注目する必要がある |
まとめ
【GPTの特徴】
- GPT-1:「言語モデル」というタスクで事前学習を行う。
- GPT-3:One-Shot Learningの学習が可能(ファインチューニングを使用しない)
- GPT-3:モデルサイズを大きくすると、訓練に要する計算量が増加する。
最後まで読んで頂きありがとうございます。
皆様のスキルアップを応援しています!!
コメント