
- 「MobileNet」について学びたいけど理解できるか不安・・・
- 「MobileNet」についてどこから学んでいいか分からない?
- 「MobileNet」を体系的に教えて!
「MobileNet」は画像認識モデルの軽量化・高速化・高精度化を実現する画期的な技術ですが、興味があっても難しそうで何から学んだらよいか分からず勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「MobileNet」を学習する際のポイントについて解説します。
この記事を参考にして「MobileNet」が理解できれば、E資格に合格できるはずです。
<<「MobileNet」のポイントを今すぐ見たい方はこちら
目次
MobileNetの概要
- 論文タイトル
◦MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Application - 提案手法
◦ディープラーニングモデルは精度は良いが、その分ネットワークが深くなり計算量が増える。
◦計算量が増えると、多くの計算リソースが必要で、コストがかかってしまう。
◦ディープラーニングモデルの軽量化・高速化・高精度化を実現
(その名の通りモバイルなネットワーク)
◦https://qiita.com/HiromuMasuda0228/items/7dd0b764804d2aa199e4
- 近年の画像認識タスクに用いられる最新のニューラルネットワークアーキテクチャは、多くのモバイルおよび組み込みアプリケーションの実行環境を上回る高い計算資源を必要とされる。https://arxiv.org/pdf/1704.04861.pdf
一般的な畳み込みレイヤー
- 入力マップ(チャンネル数):H×W×C
- 畳込みカーネルのサイズ:K×K×C
- 出力チャンネル数(フィルタ数):M
- ストライド1でパディングを適用した場合の畳み込み計算の計算量?
この点を計算するための計算量:K×K×C×M
→ 出力マップ全体の場合:H×W×K×K×C×M
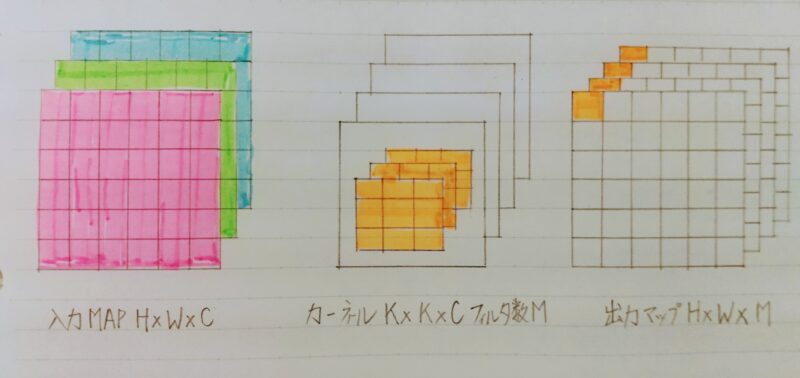
一般的な畳み込みレイヤーは計算量が多い
↓
MobileNetsは
Depthwise Convolution と Pointwise Convolution の
組み合わせで軽量化を実現
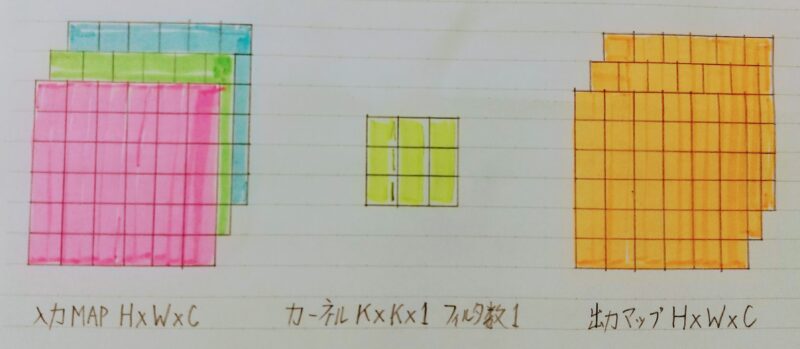
Depthwise Convolution
Depthwise Convolutionとは・・・
- 仕組み
・入力マップのチャンネルごとに畳み込みを実施
Depthwise:直訳すると「奥行き方向」
・出力マップとそれらを結合(入力マップのチャンネル数と同じになる)
(一般的な畳み込み層)出力マップの計算量は:H×W×K×K×C×M
出力マップの計算量は?:H×W×C×K×K - メリット①
一般的な畳み込みは各層ごとに畳み込みを行うので層間の関係性は全く考慮されない。
「Depthwise Convolution」と「Pointwise Convolution」をセットで使うことで解決 - メリット②
計算量が大幅に削減可能
(通常の畳み込みカーネルは全ての層にかかっているため)
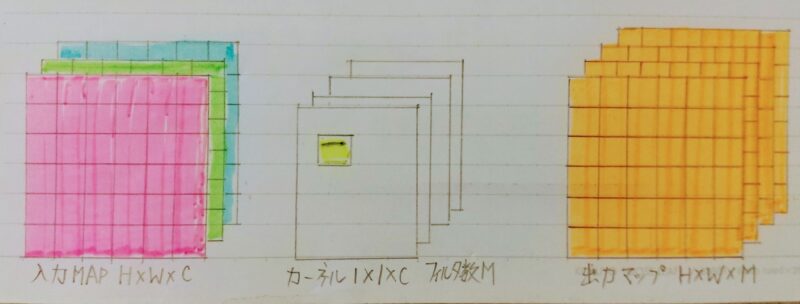
Pointwise Convolution
- 仕組み
◦1×1 conv とも呼ばれる(正確には1×1×c)
◦入力マップのポイントごとに畳み込みを実施
◦出力マップ(チャンネル数)はフィルタ数分だけ作成可能(任意のサイズが指定可能)
(一般的な畳み込み層)出力マップの計算量は:H×W×K×K×C×M
出力マップの計算量は?:H×W×C×M
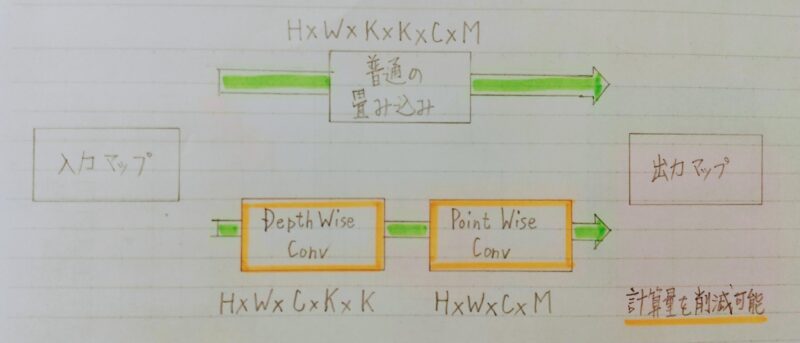
MobileNet のアーキテクチャ
- Depthwise Separable Convolutionという手法を用いて計算量を削減している。
- Depthwise Separable Convolution:
通常の畳み込み:空間方向とチャンネル方向の計算を同時に行う。
Depthwise Convolution と Pointwise Convolution と呼ばれる演算によって個別に行う。- Depthwise Convolution はチャンネル毎に空間方向に畳み込む。
⇒ チャンネル毎にDK×DK×1のサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は H×W×C×K×K となる。 - Pointwise Convolution: Depthwise Convolution の出力をチャンネル方向に畳み込む。
⇒ 出力チャンネル毎に1×1×Mサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は H×W×C×M となる。
- Depthwise Convolution はチャンネル毎に空間方向に畳み込む。
性能評価
- MobileNetはWidth multiplier α と Resolution multiplier ρ の2種類のパラメータをもつ。
- Width multiplier α:ネットワーク内のチャンネル数を調整するハイパーパラメータ
- Resolution multiplier ρ:入力画像やネットワーク内での中間表現の解像度を調整するハイパーパラメータ
- Table 6:Width multiplier α を1.0、0.75、0.5、0.25と変化させた場合のImageNetに対する認識精度、積和演算の回数、パラメータ数の変化を示す。
- Table 7:Resolution multiplier ρ を224、192、160、128と変化させた場合の各指標の変化を示す。
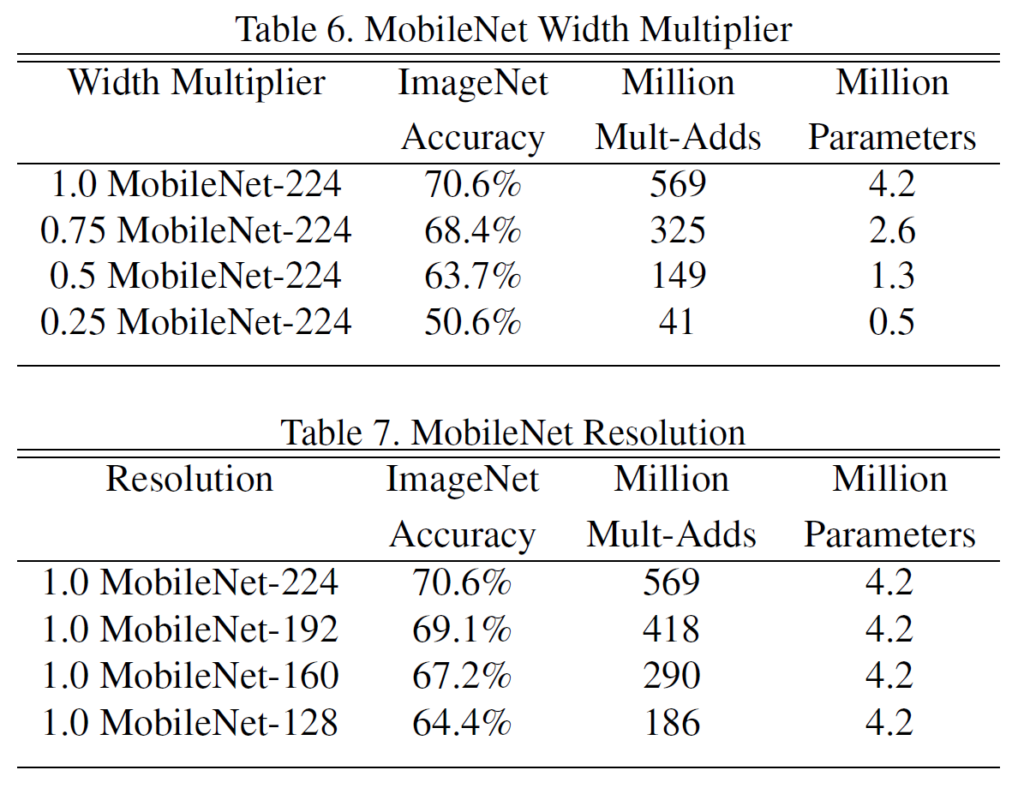
上表の引用元:https://arxiv.org/pdf/1704.04861.pdf
- 上表より Resolution multiplier ρ を変化させてもパラメータ数は変化しない。
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント