- 「人工知能(AI)」について学びたいけど理解できるか不安・・・
- 「人工知能(AI)」についてどこから学んでいいか分からない?
- 「人工知能(AI)」を体系的に教えて!
「人工知能(AI:Artificial intelligence)」は既に様々な商品・サービスに組み込まれて利活用が始まっている注目の技術ですが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格し、現在、「E資格」取得にチャレンジ中ですが、人工知能の勉強を始めた頃は多くの考え方や専門用語に圧倒され、全貌を理解するのに苦労した苦い経験があります。
そこでこの記事では、人工知能(AI)の超初心者の方へ「学習に使用するデータフレームの作成方法」について解説します。
この記事を読めば「学習に使用するデータフレームの作成方法」が理解でき、スキルアップにつながります。
なお、以降示したコードは「Google Colaboratory」というサービスを利用して実行できるか確認を行うようにしていますが未確認のものもありますのでご容赦ください。内容に誤りがあった場合はご指摘頂けると幸いです。
※1 Colaboratory(略称: Colab)は、ブラウザから Python を記述、実行できるサービス。 特徴は次のとおり
・構築環境が不要
・GPUへのアクセスが無料
・簡単に共有
Pandas.DataFrameとは?
ここでは Pandas.DataFrame というデータフレームを作成する方法を説明する。
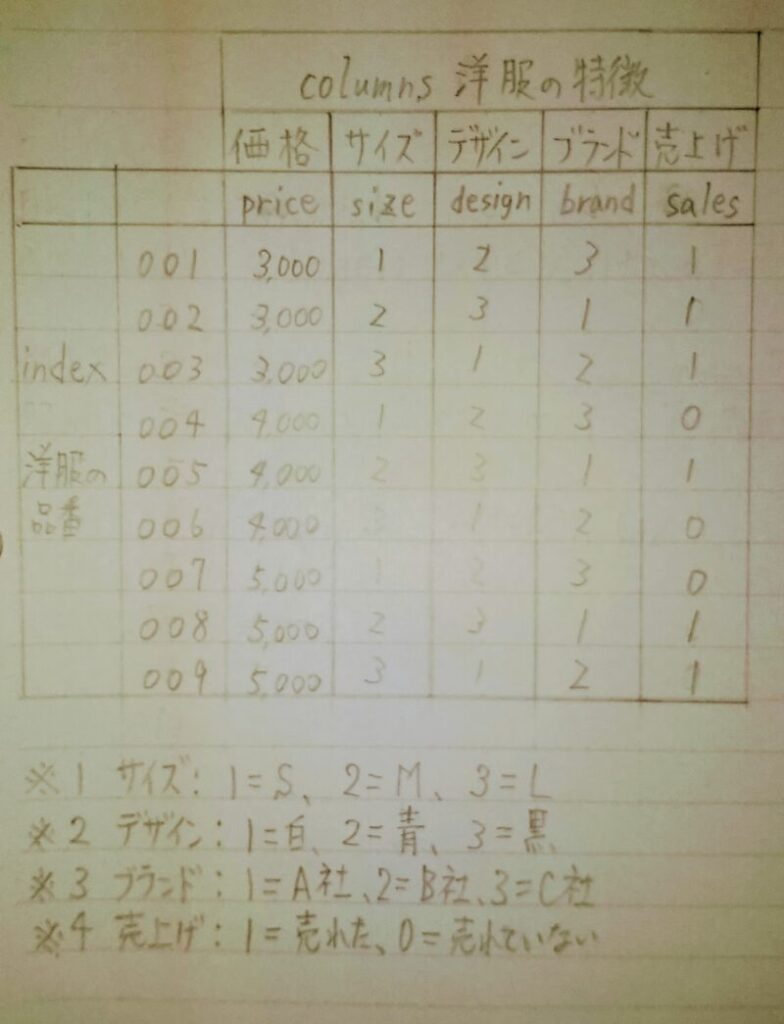
※1 Pandas.DataFrame は values、columns、indexの3つの要素から構成される。
- values:実際のデータの値であり、下表では価格の3,000であったりサイズの1が該当する。
- columns:列名(列ラベル)であり下表では価格、サイズ、デザイン、ブランド、売上げが該当する。
- index:行名(行ラベル)であり下表では洋服の品番001~009が該当する。
データフレームは行列と同じく2次元配列のデータである。下表は2次元配列の例である。
しかし、行列とは異なり列ごとに要素の単位が異なることもある。
例えば下表では価格とサイズの単位が異なっている。データを操作するとき、
この列名(columns)を使用して操作するのが一般的である。
PandasdataFrameを作成する方法には次の①~④のパターンがある。
- ①二次元配列・リストからPandasDataFrameを作成 → 1.1
- ②複数の一次元配列・リストから PandasDataFrame を作成 → 1.2
- ③辞書のリスト・辞書から PandasDataFrame を作成 → 1.3
- ④CSVファイルやExcelファイルから読み込み → 1.4
二次元配列・リストからPandasDataFrameを作成
二次元配列(リストのリスト)から PandasDataFrameを生成する例を示す。
import pandas as pd
list_2d = [[3000, 1, 2, 3, 1], [3000, 2, 3, 1, 1], [3000, 3, 1, 2, 1], [4000, 1, 2, 3, 0],
[4000, 2, 3, 1, 1], [4000, 3, 1, 2, 0], [5000, 1, 2, 3, 0], [5000, 2, 3, 1, 1],
[5000, 3, 1, 2, 1]]
df = pd.DataFrame(list_2d,
index=[‘001’, ‘002’, ‘003’, ‘004’, ‘005’, ‘006’, ‘007’, ‘008’, ‘009’],
columns=[‘price’, ‘size’, ‘design’, ‘brand’, ‘sales’])
df
price size design brand sales
001 3000 1 2 3 1
002 3000 2 3 1 1
003 3000 3 1 2 1
004 4000 1 2 3 0
005 4000 2 3 1 1
006 4000 3 1 2 0
007 5000 1 2 3 0
008 5000 2 3 1 1
009 5000 3 1 2 1
複数の一次元配列・リストからPandasDataFrame を作成
複数の一次元配列・リストから PandasDataFrame を作成するコードを以下に示す。
例:
import pandas as pd
list_2d = [[3000, 1, 2, 3, 1], [3000, 2, 3, 1, 1], [3000, 3, 1, 2, 1], [4000, 1, 2, 3, 0],
[4000, 2, 3, 1, 1], [4000, 3, 1, 2, 0], [5000, 1, 2, 3, 0], [5000, 2, 3, 1, 1],
[5000, 3, 1, 2, 1]]
df = pd.DataFrame({‘price’ :[3000, 3000, 3000, 4000, 4000, 4000, 5000, 5000, 5000],
‘size’: [1, 2, 3, 1, 2, 3, 1, 2, 3],
‘design’:[2, 3, 1, 2, 3, 1, 2, 3, 1],
‘brand’:[3, 1, 2, 3, 1, 2, 3, 1, 2],
‘sales’:(1, 1, 1, 0, 1, 0, 0, 1, 1)},
index=[‘001’, ‘002’, ‘003’, ‘004’, ‘005’, ‘006’, ‘007’, ‘008’, ‘009’])
df
price size design brand sales
001 3000 1 2 3 1
002 3000 2 3 1 1
003 3000 3 1 2 1
004 4000 1 2 3 0
005 4000 2 3 1 1
006 4000 3 1 2 0
007 5000 1 2 3 0
008 5000 2 3 1 1
009 5000 3 1 2 1
辞書のリスト・辞書からPandasDataFrame を作成
辞書のリスト・辞書からPandasDataFrame を作成する方法を以下に示す。 Pythonの辞書とは、ディクショナリ(dictionary)型と呼ばれる配列の一種。任意の数の要素を代入でき、作成後、要素の追加や削除ができる。keyとvalueの2つで1つの要素という考え方で、1つのディクショナリの中で同じkeyを使用することができない。keyとは下記の例ではprice、valueとは3000ということになる。
例:keyを列に値を行に変換する
import pandas as pd
clothes_dict_001 = {‘praice’:3000, ‘size’:1, ‘design’:2, ‘brand’:3, ‘sales’:1} # 辞書001
clothes_dict_002 = {‘praice’:3000, ‘size’:2, ‘design’:3, ‘brand’:1, ‘sales’:1} # 辞書002
clothes_dict_003 = {‘praice’:3000, ‘size’:3, ‘design’:1, ‘brand’:2, ‘sales’:1} # 辞書003
clothes_dict_004 = {‘praice’:4000, ‘size’:1, ‘design’:2, ‘brand’:3, ‘sales’:0} # 辞書004
clothes_dict_005 = {‘praice’:4000, ‘size’:2, ‘design’:2, ‘brand’:1, ‘sales’:1} # 辞書005
clothes_dict_006 = {‘praice’:4000, ‘size’:3, ‘design’:3, ‘brand’:2, ‘sales’:0} # 辞書006
clothes_dict_007 = {‘praice’:5000, ‘size’:1, ‘design’:1, ‘brand’:3, ‘sales’:0} # 辞書007
clothes_dict_008 = {‘praice’:5000, ‘size’:2, ‘design’:2, ‘brand’:1, ‘sales’:1} # 辞書008
clothes_dict_009 = {‘praice’:5000, ‘size’:3, ‘design’:2, ‘brand’:2, ‘sales’:1} # 辞書009
上記の「辞書」をPandasFrameに変換する。
df1 = pd.DataFrame([clothes_dict_001]) # 辞書001をPandasFrameに変換
df2 = pd.DataFrame([clothes_dict_002]) # 辞書002をPandasFrameに変換
df3 = pd.DataFrame([clothes_dict_003]) # 辞書003をPandasFrameに変換
df4 = pd.DataFrame([clothes_dict_004]) # 辞書004をPandasFrameに変換
df5 = pd.DataFrame([clothes_dict_005]) # 辞書005をPandasFrameに変換
df6 = pd.DataFrame([clothes_dict_006]) # 辞書006をPandasFrameに変換
df7 = pd.DataFrame([clothes_dict_007]) # 辞書007をPandasFrameに変換
df8 = pd.DataFrame([clothes_dict_008]) # 辞書008をPandasFrameに変換
df9 = pd.DataFrame([clothes_dict_009]) # 辞書009をPandasFrameに変換
※1上記のデータフレーム clothes_dict_001~009は上表「 Pandasデータフレームの例 」を行単位にしたものであり、 clothes_dict_001~009 を次に結合する。行単位の結合(UNION)の場合、「concat」を使う。
df_1_9 = pd.concat([df1, df2, df3, df4, df5, df6, df7, df8, df9], ignore_index = True)
df1_9
price size design brand sales
0 3000 1 2 3 1
1 3000 2 3 1 1
2 3000 3 1 2 1
3 4000 1 2 3 0
4 4000 2 3 1 1
5 4000 3 1 2 0
6 5000 1 2 3 0
7 5000 2 3 1 1
8 5000 3 1 2 1
※1 concat:2つ以上の複数のDataFrameをまとめて結合することができる。引数ignore_indexでは、元のDataFrameのインデックスを破棄して新たに振りなおす場合、Trueを指定し、元のインデックスを継承する場合はFalseを指定する。何も指定しないとFalseになる。
ファイルからのデータの読み込み
AIで扱うファイルは「csv形式」または「json形式」であるため各々の読み込み方法について解説する。csv形式とjson形式の違いを下記の図に示す。
- ※1 csv:「comma separated values」の略称で、値や項目をカンマ(,)で区切って書いたテキストファイル・データ。 ファイルの拡張子は「.csv」となり、様々なソフトで開くことができるのが特徴。
- ※2 json:「JavaScript Object Notation (JSON)」 は表現用の標準的なテキストベースの構造データ表現フォーマットで、JavaScript 構造データオブジェクトの表記法をベースとしている。 一般的にはウェブアプリケーションでデータを転送する場合に使われる。
なお、読み込んだデータはPandas.DataFrameというオブジェクト(様々な値や処理を一まとめにしたもの)に変換する。

↓変換
学習データの保存場所を知る
一般的な場合
AIで使用する学習データはファイルとして任意の場所に保存されているが、保存場所を知る必要がある。このためosライブラリを使って現在のディレクトリのファイルパス(絶対パス)を取得する。 例: import os print(os.path.abspath(“.”))
- ※1 import os :主にファイルやディレクトリ操作が可能で、ファイルの一覧やpathを取得できたり、新規にファイル・ディレクトリを作成することができる。
- ※2 os.path.abspath(“.”) : abspath はos.pathモジュールに含まれている。引数で指定したパスの絶対パスを返す手法。
- ※3 モジュール:関数やクラスが定義されているもの
- ※4 ファイルの絶対パスを取得する方法:上記の他にWindowsではファイ名上で「SHIFT+右クリック」すると「パスのコピー」というメニューが現れ絶対パスを取得できる。
Google Colabを使用する場合
Google Colabを使用する場合、ローカル環境のファイルを読み込むことができない。理由はGoogle Colabはインターネット上で実行するため。なので工夫して読み込ますことが必要になる。
- ①Google Colab でGoogleドライブをマウントする。
- ②Google ドライブに読み込むファイルをアップロードする。
- ③Google Colab でファイルを読み込む。
以降①~③を順番に説明する。
- ①Google Colab でGoogleドライブをマウントする
from google.colab import drive drive.mount(‘/content/drive’)
- ②Google ドライブに読み込むファイルをアップロードする
「train_data.csv」というcsvファイルをアップロードします。
- ③Google Colab でファイルを読み込む(参考)
import csv
csvfile = open(‘/content/drive/My Drive/○○/train_data.csv’, ‘r’,
encoding=’utf-8′)
reader = csv.DictReader(csvfile)
for row in reader:
print(row)
※1 open関数はファイルの新規作成や保存、書き込みなどファイル操作ができる。
open関数の形式は次のとおり。
open(ファイル名, オプション, 文字エンコード)
文字エンコードとはファイルに書き込む際にコンピュータ上で文字や記号を扱う際に割り振らている番号のことでUTF-8やShift-JISなどがある。
ファイルの読み込み
csv形式ファイルの読み込み
csv形式の場合は次のようになる。 例:
import pandas as pd
train_path =’○○/○○/○○.csv’
#csvデータの内容からPandasで処理可能なDataFrameオブジェクトを作成する
df = pd.read_csv(train_path)
#オンライン上にあるcsvデータを参照する場合はそのcsvのリンクを引数に指定しても参照できる。そのまま読み込むとcsvの1行目が列名として扱われる。
※2 オブジェクト(Object) :整数や実数、文字列などのデータのことを、オブジェクトという用語で呼ぶ。Pythonが操作するいろいろな種類のデータやプログラムなどのことを、まとめてオブジェクトと呼ぶ。 ※3 pd:Pandasはデータ操作によく用いられるパッケージ。csvなどの一般的なデータ形式で保存されたデータの読み込み等に使用する。 ※4 csvの()内はパス名になるが長くなるので先のようにtrain_pathというような変数に代入すると入力する手間が省ける。
json形式ファイルの読み込み
私の経験ではcsv形式のファイルを取り扱うことがほとんどであったが、稀にファイル形式がjson形式の場合がある(自然言語処理の場合等)。この場合の読み込む方法は次のとおりとなる。次のコードはjson文字列を辞書に変換することができる。
例: inport pandas as pd
json.pd.read_json( ‘../○○/train_data.json’, encoding=”UTF-8″ ) #JSONファイルを読み込む df.to_csv( ‘../○○/train_data.csv’ ) #〈参考〉JSON形式に変換し保存
読み込んだデータをPyTorchテンソルに変換する方法
PyTorchの場合、データ形式として「Pytorchテンソル」を使用するのが標準である。上記で読み込んだPandasデータフレームをPytorchテンソルに変換するコードについて次に説明する。なお、 Pytorchテンソルへの変換にあたってはデータの型を Pytorchテンソルへ対応する型に変換する必要がある。 Pytorch のデータ型(torch.dtypes)には様々あるが基本的に使うのは下記の2種類である。
・32bitの浮動小数点:torch.float ・32bitの符号付き整数:torch.int
import pandas as pd import torch import random
targets_data = [random.random() for i in range(10)]
targets_df = pd.DataFrame(data=targets_data) targets_df.colums =[‘targets’]
torch_tensor = torch.tensor(targets_df[‘targets’].values)
※1 pytorchテンソル:pyTorchが用意している特殊な型でTensor型というものを使用する。実際にはnumpyのndarray型ととても似ており、ベクトル表現から行列表現それらの演算といった機能が提供されている。特徴はGPUを使用して演算等が可能であること。
【データフレームの作成方法】
- Pandas.DataFrameとは?
Pandas.DataFrame は values、columns、indexの3つの要素から構成 - 学習データの保存場所を知る
- ファイルの読み込み
- 読み込んだデータをPyTorchテンソルに変換する方法
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント