
- 「Seq2Seq」について学びたいけど理解できるか不安・・・
- 「Seq2Seq」についてどこから学んでいいか分からない?
- 「Seq2Seq」を体系的に教えて!
人工知能(AI)における自然言語処理の手法である「Seq2Seq(Sequence To Sequence)」は機械対話や、機械翻訳などに使用されていますが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「Seq2Seq」の要点を解説します。
この記事を参考にして「Seq2Seq」の要点が理解できれば、E資格に合格できるはずです。
<<「Seq2Seq」に関する学習のポイントを今すぐ知りたい方はこちら
Seq2Seq
- EncorderーDecorderモデルの一種を指す。
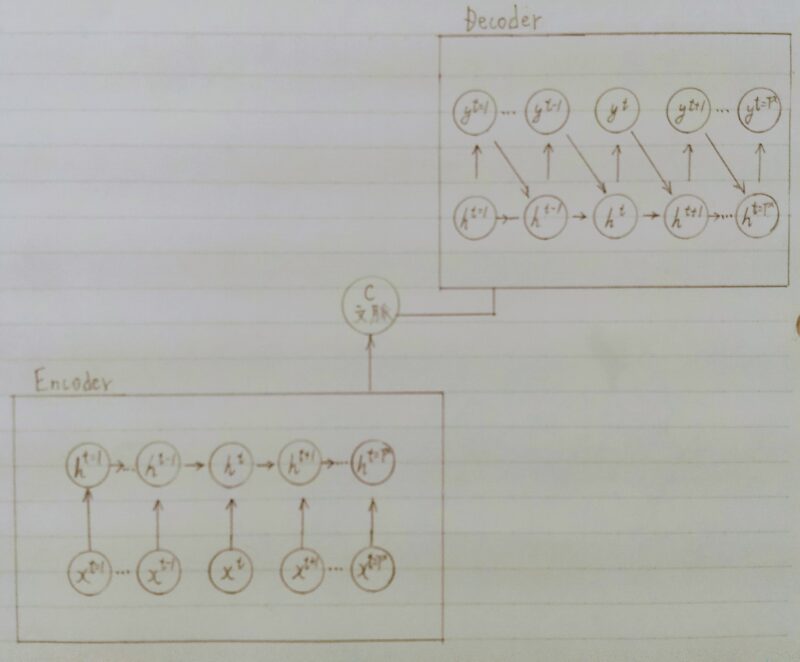
- 具体的な用途
機械対話や機械翻訳などに使用されている。
Encoder RNN
- Encoder RNNとはユーザーがインプットしたテキストデータを、単語等のトークンに区切って渡す構造。
補足)トークン(token)とは直訳すると「しるし」「象徴」のこと。
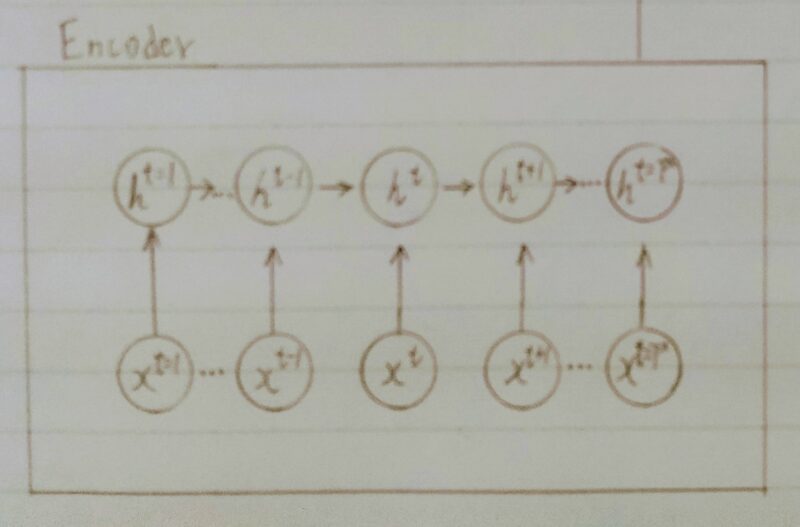
Taking:文章を単語等のトークン毎に分割し、トークン毎のIDに分割する。
Embedding:IDから、そのトークンを表す分散表現ベクトルに変換。
Encoder RNN:ベクトルを順番にRNNに入力していく。
食べ 刺し 大丈 でし 。
た 身 夫 たか
| 単語 | ID | oneーhot 10,000 | embedding ~数百 |
|---|---|---|---|
| 私 | 1 | [1,0,0・・・0] | [0.2 0.4 0.6・・・0.1] |
| は | 2 | [0,1,0・・・0] | [ ・・・ ] |
| 刺身 | 3 | [0,0,1・・・0] | [ ・・・ ] |
| 昨日 | 4 | [ ・・・ ] | [ ・・・ ] |
| ・ ・ ・ | ・ ・ ・ | ・ ・ ・ | ・ ・ ・ |
| ××× | 10,000 | [0,0,0 ・・・ 1] | [ ・・・ ] |
- vec1をRNNに入力し、hidden stateを出力。
このhidden stateと次の入力vec2をまたRNNに入力してきたhidden stateを出力という流れを繰り返す。 - 最後のvecを入れたときのhidden stateをfinal stateとしてとっておく。
このfinal stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる。
BERT(Googleが開発した自然言語処理モデル)
↑ MLMーMasked Language Modelを採用
私 は 昨日 ラーメン を 食べ ました
[・・・] [・・・] [・・・] [・・・] [・・・] [・・・] [・・・]
×
Decoder RNN
- Decoder RNNとはシステムがアウトプットデータを、単語等のトークンごとに生成する構造。
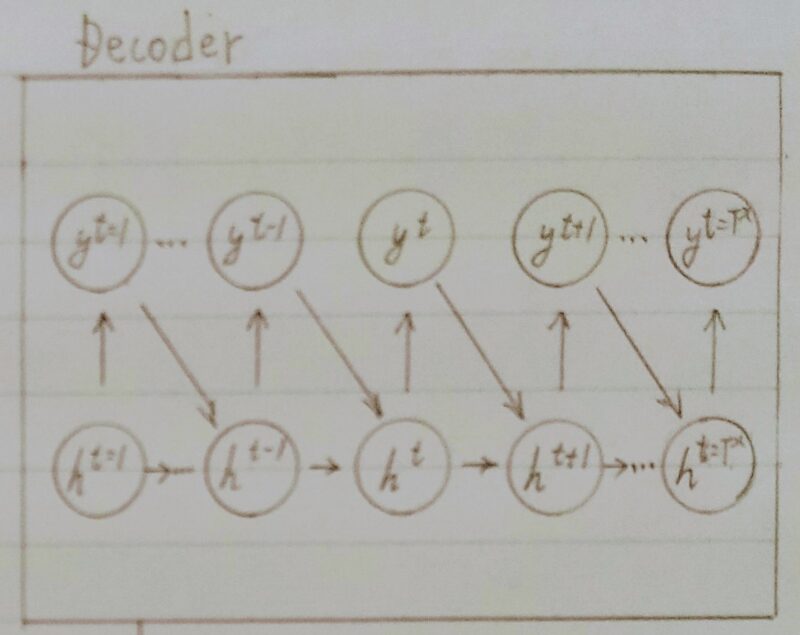
- Decoder RNN:Encoder RNN の final state(thought vector)から、
各tokenの生成確率を出力していくfinal state を Decorder RNN のinitial state
として設定し、Embedding を入力。 - Sampling:生成確率にもとづいて token をランダムに選ぶ。
- Embedding: 2で選ばれた token を Embedding して Decoder RNN への次の入力とする。
- Detokenize: 1-3 を繰り返し、2で得られた token を文字列に直す。
問題1
Q.下記の選択肢から、Seq2Seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
A.(2)
問題2
Q.機械翻訳タスクにおいて、入力は複数の単語から成る文(文章)であり、それぞれの単語はone-hotベクトルで表現されている。Encoderにおいて、それらの単語は単語埋め込みにより特徴量に変換され、そこからRNNによって(一般にはLSTMを使うことが多い)時系列の情報をもつ特徴へとエンコードされる。以下は、入力である文(文章)を時系列の情報をもつ特徴量へとエンコードする関数である。ただし_activation関数はなんらかの活性化関数を表すとする。(き)にあてはまるものはどれか。
def encode(word, E, W, U, b):
“””
words: sequence words(sentence), onehot vector, (n_words, vocab_size)
E: word embeding matrix, (embed_size, vocab_size)
W: upward weight, (hidden_size, hidden_size)
U: lateral weights, (hidden_size, embed_size)
b: bias, (hidden_size,)
“””
hidden_size = W.shape[0]
h = np.zeros(hidden_size)
for w in word:
e = (き)
h = _activation(W.dot(e) + U.dot(h) + b)
return h
A.E.dot(W)
〈補足〉dot()関数はベクトルの内積や行列の積を計算する関数
E.dot(W)は行列EとベクトルWの積を求めている。
機械翻訳の評価
- BLEUの定義

- BP(Brevity Penalty)は c<r の場合にペナルティが科せられている。
Brevity:直訳すると「簡潔な」 - 対数加重平均をとる理由
・Pn(modified n-gram precision)は指数的に小さくなる傾向がある。
→対数加重平均をとって平坦化
・nが小さい時のスコア・・・妥当性を評価
・nが大きい時のスコア・・・流暢性を評価
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント