
- 「距離学習(Metric-learning)」について学びたいけど理解できるか不安・・・
- 「距離学習(Metric-learning)」についてどこから学んでいいか分からない?
- 「距離学習(Metric-learning)」を体系的に教えて!
「距離学習(Metric-learning)」は、人物同定(Person Re-Identification)をはじめ、顔認識、画像分類、画像検索、異常検知など幅広いタスクに利用される技術ですが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこで、この記事では「距離学習(Metric-learning)」のポイントについて解説します。
この記事を参考に「距離学習(Metric-learning)」が理解できれば、E資格に合格できるはずです。
<<「距離学習(Metric-learning)」のポイントを今すぐ知りたい方はこちら
距離学習(Metric-learning)とは
- 距離学習(Metric-learning)の目的はデータ間のmetric(=データ間の距離)を学習する。
距離学習自体は古くからある手法 - データ間の距離を適切に測ることができるメリット
・距離が近いデータ同士をまとめてクラスタリングできる
・他のデータ要素から距離が遠いデータを異常と判定することで異常検知できるetc - ディープラーニング技術を利用した距離学習の手法が数多く提案されている。このような手法は、特に深層距離学習(Deep Metricーlearning)と呼ばれる。
応用例)人物同定(Person Re-Identification)をはじめ、顔認識、画像分類、画像検索、異常検知など幅広いタスクに利用
深層距離学習の手順
- 一般に、画像や音声などの多次元データはニューラルネットワークを用いることにより、次元削減(データ圧縮)することができる。
畳み込みニューラルネットワーク(CNN)における距離学習
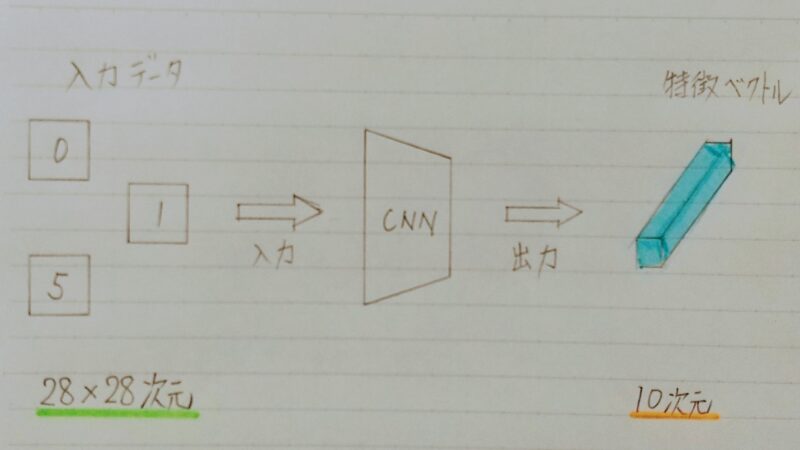
- ここでは、畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)を用いた画像分類の場合を例に挙げる。
- 28×28 サイズの画像をCNNに入力することで10次元ベクトルに 圧縮できる。→ つまり、元々28×28=784個の数値で表現されていた画像の情報を10個の変数に圧縮
- CNNから出力されるベクトルは、入力データの重要な情報を抽出したベクトルと考えるため、一般に特徴ベクトル(feature vector)と呼ばれる。
- 未学習のネットワークにデータを入力しても出力されるのは無意味なベクトル→特徴ベクトルに意味を持たせるには何らかな手法でCNNを学習する必要あり
- 深層距離学習は上記の1つの手法であり、2つの特徴ベクトル間の距離データが類似度を反映するようにネットワークを学習する。具体的には、
・同じクラスに属する(=類似)サンプルから得られる特徴ベクトルの距離感を小さくする
・異なるクラスに属する(=非類似)サンプルから得られる特徴ベクトルの距離間を大きくする - 埋め込み空間(embedding space)(=特徴ベクトルの属する空間)内で類似サンプルの特徴ベクトルは近くに、非類似サンプルの特徴ベクトルは遠くに配置されるように学習を行う。
手法1:Siamese network
- 最小化したい損失関数を下式のとおりとする。
損失関数:L =(1/2)× [yD2 + (1 − y) max(m − D, 0)2]
D:2つの入力サンプル間の距離 ←小さい程よい
y:入力が類似しているかどうかの識別ラベル ←小さい程よい
m:非類似サンプル間の距離のマージン ←正の値をとり小さい程よい - 上記の損失関数Lは特に constructive loss と呼ばれる。
補足)constructive :直訳)建設的な - ペア画像が同じクラスの場合には距離Dが小さくなるように、逆に異なるクラスの場合には大きくなるように損失関数Lを設計する。
m<Dの場合、損失関数は最小になるかな?
m-D<0になるのでmax(m-D,0)=0だから、損失関数が最小になるよ!
手法2:Triplet network
最小化したい損失関数を下式のとおりとする。
損失関数:L = max (Dp − Dn + m, 0)
Dp:アンカーサンプルと類似サンプル間の距離 ←小さい程よい
Dn:アンカーサンプルと非類似サンプル間の距離 ←小さい程よい
m:類似サンプルと非類似サンプル間の距離のマージン ←正の値をとり小さい程よい
上記の損失関数は特に Triplet loss と呼ばれる。
損失関数LでDpはプラスしてDnはマイナスするのかな?
まず、損失関数Lを最小化することが目的だよ。
Dpが小さいとDnは大きくなり、Dp − Dn<0になるからだよ!
- 同じクラスのデータの距離Dpを0にする必要はない。つまりDpとDnそれぞれに対する条件をなくし、あくまでDpとDnを相対的に最適化することで上記1の不均衡を解消している。
- 基準となる画像(=アンカーサンプル)に対して類似度が低いサンプルをもう一方のサンプルより遠ざけることになるため、コンテキストを考慮する必要がない。
- 学習がすぐに停滞してしまう
- 学習データセットのサイズが増えてくると考えうる入力の組み合わせが膨大になる。
- 殆どの組み合わせが学習が進むにつれてパラメータ更新に影響を及ぼさなくなる。
- クラス内距離がクラス間距離より小さくなることを保証しない
手法3:Siamese networkとTriplet networkの比較
| Siamese network | Triplet network | |
|---|---|---|
| メリット | ・類似しない2つのサンプル間の距離が全てのマージンの値に収束するよう学習が行われる。 | ・同じクラスのペアと異なるクラスのペアの間の不均衡を解消 ・コンテキスト(context)の考慮が不要 |
| デメリット | ・同じクラスのペアと異なるクラスのペアの間に不均衡発生 ・学習時のコンテキスト(context)に関する制約あり | ・学習データセットのサイズが増えると入力の組み合わせが膨大 ・学習時の入力ペアの選び方に、学習されたモデルの性能に依存 |
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント