- 「人工知能(AI)」について学びたいけど理解できるか不安・・・
- 「人工知能(AI)」についてどこから学んでいいか分からない?
- 「人工知能(AI)」を体系的に教えて!
「人工知能(AI:Artificial intelligence)」は既に様々な商品・サービスに組み込まれて利活用が始まっている注目の技術ですが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。人工知能の勉強を始めた頃は多くの考え方や専門用語に圧倒され、1回目のG検定に不合格となり理解するのに苦労した苦い経験があります。
そこでこの記事では、データセットを訓練データとテストデータに分割する方法についてポイントを解説します。
この記事を参考にしてデータセットを訓練データとテストデータに分割する方法を理解できれば、G検定に合格できるはずです。
1.AIモデルの評価方法
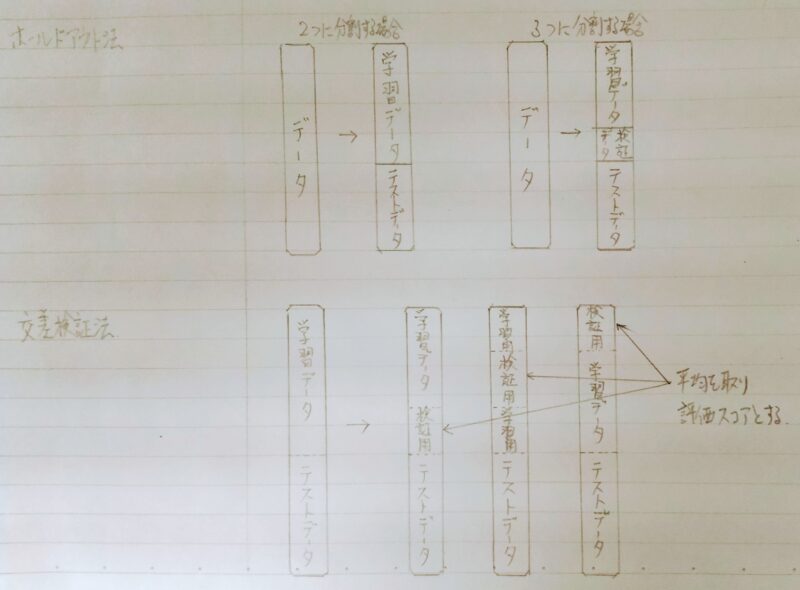
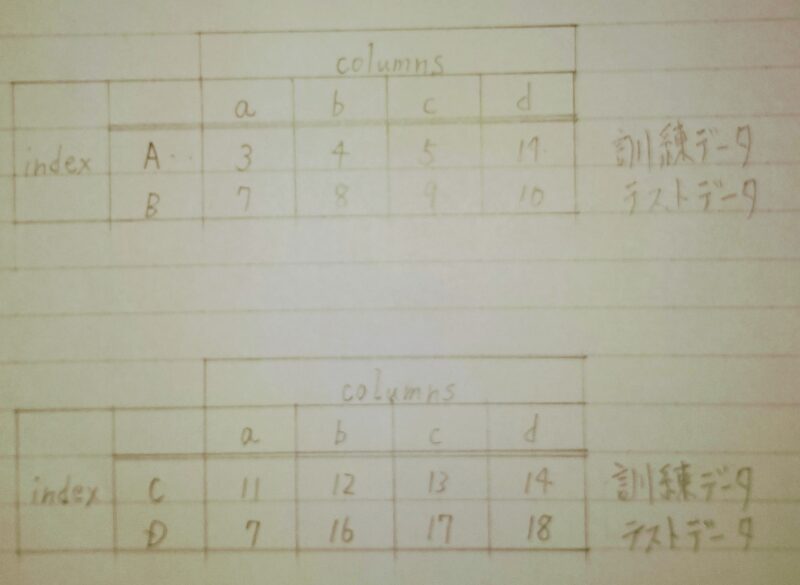
データセットを訓練データとテストデータに分割する理由は、訓練データで学習したAIモデルをテストデータを用いて評価するためである。 また、さらに訓練データを訓練データとテストデータに分割するケースもある。その理由は検証用データで1度モデルの評価を行い、モデルのパラメータを調整して最終的なモデルを決定し、テストデータで評価を行うためである。下図は代表的な分割方法を示す。
余談:勉強方法)あなたはこんな経験はないだろうか?試験勉強をするとき過去問題を解くと思うが、例えば過去問題が10年分あった場合にどのような学習方法が効果的であるだろうか?AIでは10年分のうち〇年分を訓練データとして学習し、残り〇年分をテストデータとして本当に学習がうまくいっているか検証するのである。私がこれまで試験勉強をしている時は全くこのような発想はなく、ただ漠然と過去問題を解いていた。言われてみればAIの学習方法は理にかなっていると思う。単純に過去問題が解けるようになっただけでは本当に実力が付いているか分からないからである(過去問題に慣れただけで新しい問題への対応能力があるかどうか不明)。なるほどと思われた方は是非実際の試験勉強でも試してみられることをお勧めする。
データを分割して評価する方法には次の2種類がある。
- ①ホールドアウト交差検証:
訓練データ(学習データ)とテストデータ(評価用データ)に分割 - ②kー分割交差検証:
訓練データ・テストデータの分割を複数回行い、それぞれで学習・評価。
2.ホールドアウト検証
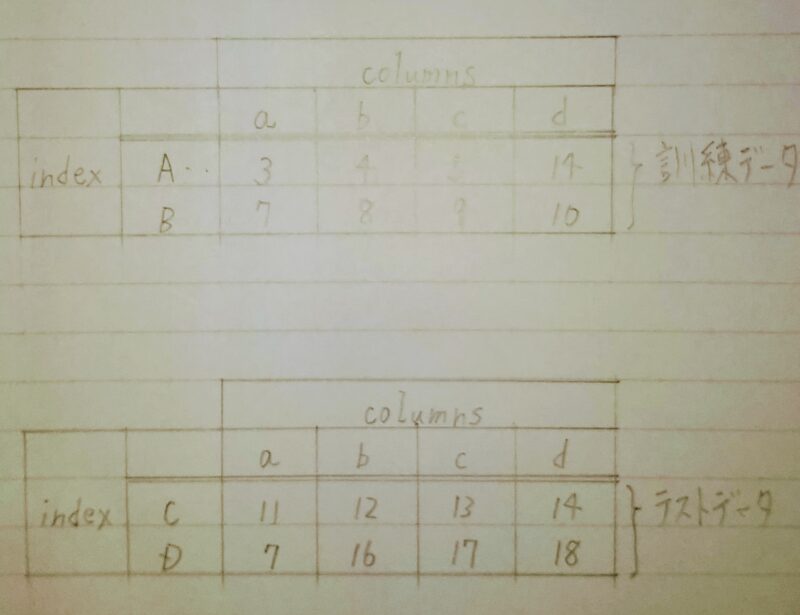
scikit-learnに用意されているメソッドを使用して、「3.データの欠損値の補完」で取り扱ったPandasDataFrameを訓練用データとテスト用データに分割する。
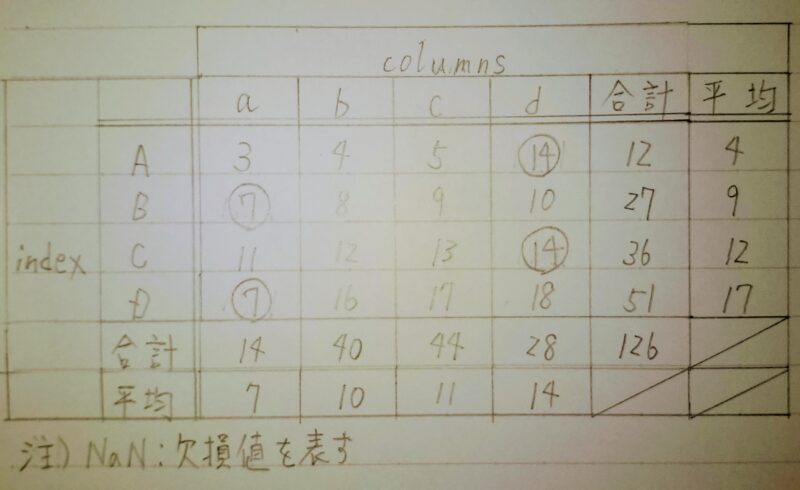
↓訓練データとテストデータに分割
例: import pandas as pd from sklearn.model_selection import train_test_split
df = pd.read_csv(‘○○/○○/○○.csv’)
df_train, df_test = train_test_split(df, test_size=0.5, random_state=0)
※1 train_test_split()関数:NumPy配列、リスト、Pandasの DataFrame を二分割できる。機械学習においてデータを訓練用(学習用)とテスト用に分割してホールドアウト検証を行う際に用いる。 ※2 引数test_size:テスト用(返されるリストの2つめの要素)の割合または個数を指定できる。デフォルトはtest_size=0.25で25%がテスト用、残りの75%が訓練用となる。小数点以下は切り上げとなり、上の例では10*0.25=2.5→3となっている。 ※3 引数random_state:シャッフルされる場合、デフォルトでは実行するたびにランダムに分割される。乱数シードを固定すると常に同じように分割される。
3.kー分割交差検証
scikit-learnに用意されているメソッドを使用して、「3.データの欠損値の補完」で取り扱ったPandasDataFrameをk=2個に分け、n=1個の訓練用データとk-n=1個のテスト用データに分割する。
↓訓練データとテストデータに分割
例: import pandas as pd from sklearn.model_selection import KFold
df = pd.read_csv(‘○○/○○/○○.csv’)
kf = KFold(n_splits=n, shuffle=True)
※1 KFold()関数:データをk個に分け、n個を訓練用、k-n個をテスト用として使う。 ※2 引数n_split:データの分割数。検定はここで指定した数値の回数おこなわれる。 ※3 引数shuffle:Trueなら連続する数字でグループ分けせず、ランダムにデータを選択する。 ※4 引数random_state:乱数のシードを指定できる。
4.まとめ
【モデルの評価方法】
- ホールドアウト検証
- kー分割交差検証
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント