
- 「ResNet」について学びたいけど理解できるか不安・・・
- 「ResNet」についてどこから学んでいいか分からない?
- 「ResNet」を体系的に教えて!
「ResNet(Residual Net)」は、「Residual module」、「batch normalization」、「Heの初期化」を利用し、2015年にILSVRC(物体検出コンペティション)において優勝した深層学習モデルですが、興味があっても難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「ResNet」の学習のポイントを解説します。
この記事を参考にして「ResNet」が理解できれば、E資格に合格できるはずです。
1.効率的な学習方法とは
- 転移学習(Transfer Learning)
教師あり学習において、目的とするタスク(課題)での教師データが少ない場合に、別の目的で学習した学習済みモデルを再利用 - 「異なるドメイン(=領域)の学習結果」を利用
異なるドメイン(=領域)のデータで高精度の学習済みモデルがある場合・・・
- そのモデルの構造は似たタスクでも有効ではないか?
- 学習済みモデルを別タスクでそのまま利用できるのではないか?
- 「事前学習」した情報から始めた方が学習が効率的になるのではないか?
- ImageNetは1400万件以上の写真のデータセット。
- 様々なAI/MLモデルの評価基準になっており、学習済みモデルも多く公開されている。
- 参照元:https://cs.stanford.edu/people/karpathy/cnnembed/
ImageNetを1000分類で分類した教師データを利用。
ResNetにより学習。以下はサンプル
| No. | Index | Label |
|---|---|---|
| 1 | 0 | tench, Tinca tinca |
| 2 | 1 | goldfish, Carassius auratus |
| 3 | 2 | great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias |
| 4 | 3 | tiger shark, Galeoceydo cuvieri |
| 5 | 4 | hammerhead, hammerhead shark |
ImageNet学習済みモデルの概要(ResNet抜粋)
| No. | Model | Size | Top-1 Acc | Params |
|---|---|---|---|---|
| 1 | ResNet50 | 98MB | 0.749 | 25,636,712 |
| 2 | ResNet101 | 171MB | 0.764 | 44,707,176 |
| 3 | ResNet152 | 232MB | 0.766 | 60,419,944 |
2.ResNet
- 「Residual Net」のこと
Residual:直訳すると「残留物」
【工夫】「Skip Connection」+「Bottleneck構造」を導入 - メリット
勾配消失問題の回避
勾配爆発の回避 - 2015年にILSVRC(物体検出コンペティション)において優勝
【分類誤差】3.6%
2.1 Skip Connection
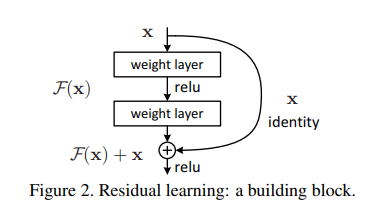
- 深い層の積み重ねでも学習可能に
◦勾配消失問題の回避
◦勾配爆発の回避 - 中間層の部分出力:H(x)
- 残差ブロック(Residual Block):
H(x)=F(x)+x - 学習部分:F(x)
Skip Connection:上図よりバイパス接続(=Identity mapping)をすること。
Identity mapping:日本語に直訳すると「身元の位置付けを割り当てる」
- ブロックへの入力にこれ以上の変換が必要ない場合は重みが0となる。
⇒ 浅いCNN(畳み込みニューラルネットワーク)で十分学習ができてしまい、深い中間層が不要な際、不要な層の重みが0になる。 - 小さな変換が求められる場合は対応する小さな変動をより見つけやすくなる。
入力時点の勾配が小さい値の場合、通常であればレイヤーを重ねていくほど勾配が消失していってしまうが、「Skip Connection」によりわずかな勾配の情報を消失することなく残すことができる。
⇒ 層を深くしても学習を進めることが可能
2.2 Bottleneck構造
Plainアーキテクチャ Bottleneckアーキテクチャ
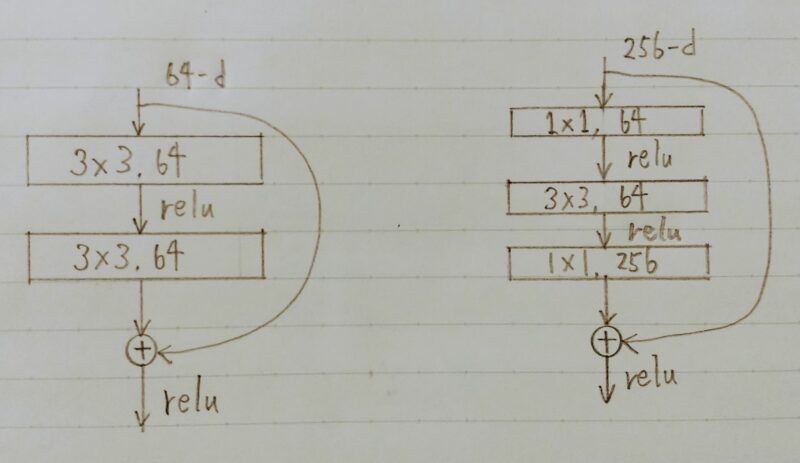
- 同一計算コストで1層多い構造
- 途中の層で3×3の畳込みを行う
3.Wide ResNet
3.1 構造
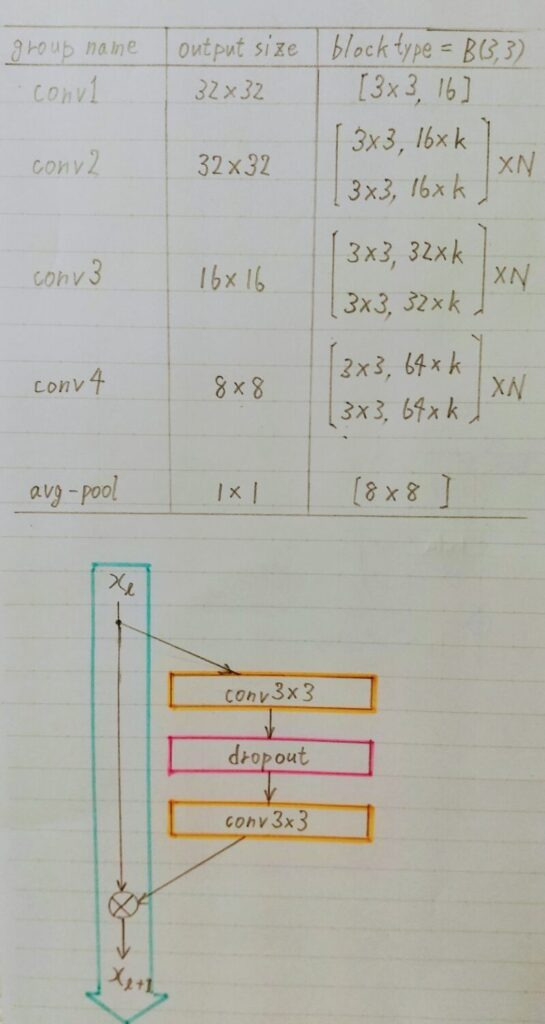
3.2 事前学習で利用するモデル
事前学習で利用するモデルは Wide ResNet
- 画像分類におけるベースモデルとしてしばしば用いられる。
例)学習済みWide ResNetをベースとして転移学習を行い新たなモデルを構築する。 - フィルタ数をk倍したResNet。
- パラメータ数を増やす方法として、層を深くするのではなく、各層を広く(Wide)した。
以下の表は、CIFAR-10、CIFAR-100 データセットに対する、パラメータdepth、kを変えた時のWide ResNet のエラー率を示している。
下表より、kの値が同じ場合、depthの値が大きい方がエラー率が必ず小さくなるとはいえない。
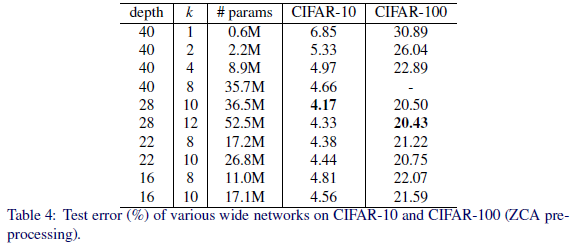
上表参照元:https://arxiv.org/abs/1605.07146
3.3 ファインチューニング
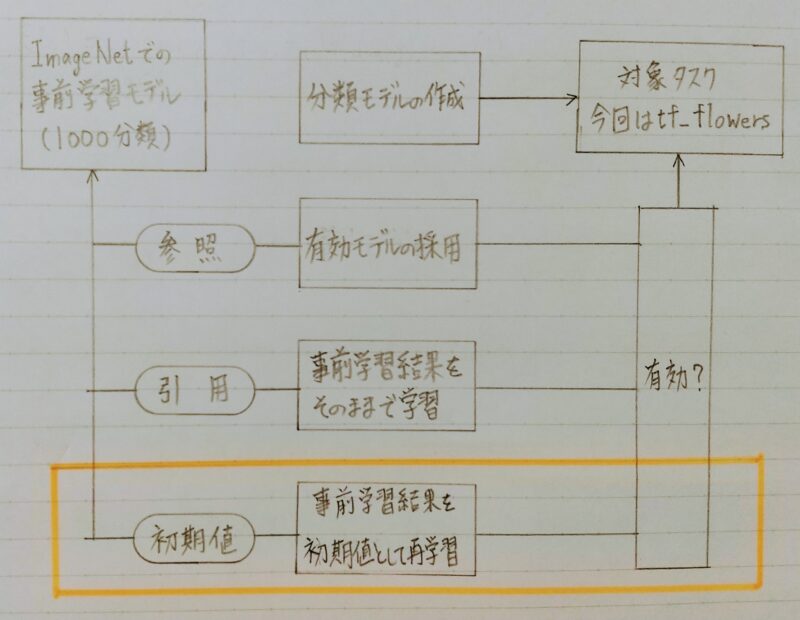
4.まとめ
以上
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント