
- 「RーCNN」について学びたいけど理解できるか不安・・・
- 「RーCNN」を使うメリットが分からない?
- 「RーCNN」を体系的に教えて!
「RーCNN(Regional CNN)」は物体検出と物体認識を行うアルゴリズムの原形になる手法ですが、よく理解できないケースが非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「RーCNN」のポイントについて解説します。
この記事を参考にして「RーCNN」が理解できれば、E資格に合格できるはずです。
目次
1.物体検出の概要
物体検出とは・・・
- 物体検出の内容
・特徴を抽出
・対象物の領域を切り出す
・クラスを認識 - 物体検出の流れ
2段階検出器の場合の下記の手順で行う。
①物体の同定(identification):画像の中で物体がどこにあるのか?
②物体認識分類(classification):何の物体であるか? - 物体検出はバウンディングボックスを使用
長方形で関心領域を切り出す
4座標を予測する回帰問題
2.Semantic Segmentation(意味領域分割)
- 物体領域を画素(ピクセル)単位で切り出し、各画素にクラスを割り当てる手法
- 主要手法:完全畳み込みネットワーク(FCN:Fully Convolutional Network)
・全ての層が畳み込み層、全結合層を有しない
・画素(ピクセル)ごとにラベル付した教師データを与えて学習する→出力ノードが多数
・未知画像も画素単位でカテゴリを予測する
・入力画像のサイズは可変で良い - 重要な学習データセットに、VOC2012とMSCOCOがある。
- 応用分野:工業検査や医療画像解析などの精密な領域分割
3.R-CNN(Regional CNN)
R-CNNの概要
- R-CNN(Regional CNN)
Regional・・・直訳すると「地域」 - 「物体検出」+「物体認識」のアルゴリズムの原形
2段階検出器(「物体検出タスク」と「物体認識タスク」を順次行う ) - 出典元:https://arxiv.org/pdf/1311.2524.pdf
RーCNNのステップ
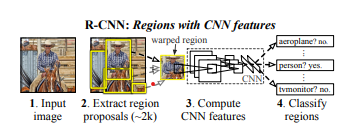
出典元:https://arxiv.org/pdf/1311.2524.pdf
- Input image
画像を入力 - Extract region proposals(~2k)
検出可能と予想される領域を約2000個ほど提案(カテゴリに依存しない)- 候補領域を取得 ← Selective Search(選択的探索法)
- 3.に渡される前に候補領域をリサイズする。(アスペクト比は保たれない。)
- Compute CNN features
CNN(畳み込みニューラルネットワーク)を使用して、画像特徴を固定長の特徴ベクトルに変換 - Classify regions
特徴ベクトルの所属するクラスを特定- クラス分類 ← 線形サポートベクターマシン(SVM)
- 評価指標としてIoU(Intersection over Union)が用いられる。
SelectiveSearchとは・・・
引用元:Quiita
画像の中から、”物体らしい”箇所を検出するタスク。おおまかな流れとして、矩形を複数用意し、画像の上をスライディングさせていき、”物体らしい”箇所を見つけ出す。物体が何であるかや特定の物体だけを検出するわけではない点に注意。例えば画像の中から車だけを見つけ出すことはできない。
R-CNNの課題
- 処理が重くて遅い
理由:多数の物体領域に対し複雑な処理を行うため - EndーtoーEnd(一気通貫)な学習ができない
理由:CNN(特徴抽出)とSVM(カテゴリ推定)など各学習の目的ごとに別々に学習 するため
R-CNNの課題に対する解決策
- Fast R-CNN(高速R-CNN)
計算量を大幅に減少
理由:画像ごとに1回の畳み込み操作を行うため
(関心領域ごとに畳み込み層に通すのではない) - Faster R-CNN
・関心領域の切り出しもCNNで行う
・ほぼリアルタイムで動作し、動画認識への応用される - YOLO(You Only Look Once)
領域の切り出しと物体認識を同時に行う - SSD(Single Shot Detector)
領域の切り出しと物体認識を同時に行う
4.まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント