
- 「Mask RーCNN」について学びたいけど理解できるか不安・・・
- 「Mask RーCNN」を使うメリットが分からない?
- 「Mask RーCNN」を体系的に教えて!
「Mask RーCNN(Mask Regional CNN)」はFaster R-CNNを拡張したアルゴリズムで、ICCV2017 の Best Paper に選出された優秀な深層モデルですが、よく理解できないケースが非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「Mask RーCNN」のポイントについて解説します。
この記事を参考に「Mask RーCNN」のポイントを理解できれば、E資格に合格できるはずです。
<<「Mask RーCNN」の学習のポイントを今すぐ知りたい方はこちら
目次
1.Mask R-CNNの概要
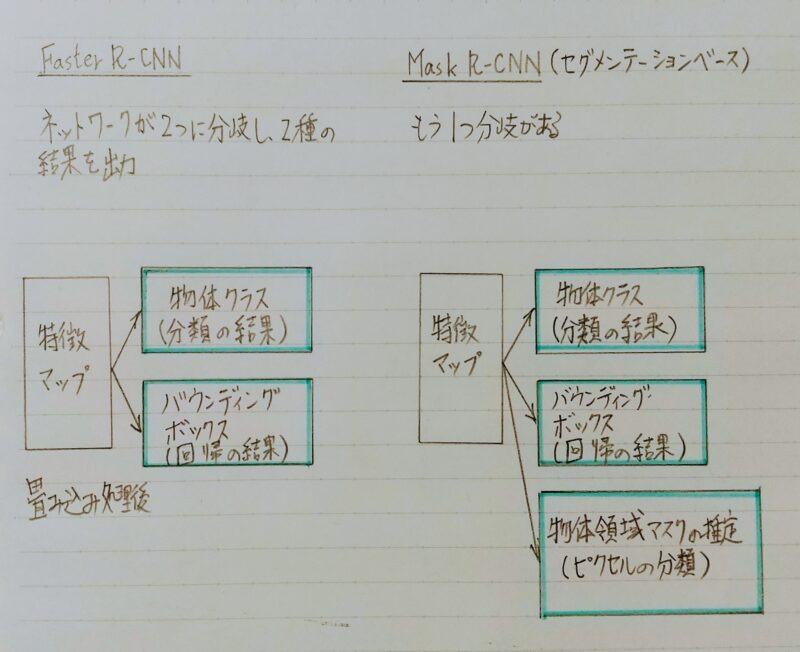
- Mask R-CNNは、Faster R-CNNを拡張したアルゴリズム
・Faster R-CNNの物体検出機能にセグメンテーションの機能を付加したイメージ - バウンディングボックス内の画素(ピクセル)単位でクラス分類を行うため、物体の形も推定可能
(原論文)https://arxiv.org/abs/1703.06870 - Mask R-CNNは、ICCV2017 の Best Paper に選出
※ICCV(International Conference on Computer Vision)はコンピュータビジョンの最高峰のカンファレンス(会議)
2.Mask R-CNNの特徴
- 画像中の「物体らしき領域」+「その領域にあるクラス」を検出
「物体らしさ」が閾値以上の領域にのみ絞り、領域毎に最も効率が高いクラスを採用 - 画像全体ではなく、物体検出の結果として得られた領域についてのみSegmentationを行うことで効率アップ ⇒ 「3.Instance Segmentation(個体領域分割)」参照
- Faster R-CNNと構造に類似点が多い
下図よりMask RーCNN の物体検出精度は、Mask R-CNN から Mask 機構を取り除いた場合と比較し、マルチタスク学習の寄与により精度が向上。
補足)マルチタスク学習とは複数の問題を単一のモデルでまとめて解く手法
3.Instance Segmentation(個体領域分割)
Instance Segmentationとは・・・
- 画像のピクセルをどのクラスに属するかに分類するのに加えて、検出したそれぞれの物体を見分け、Class ID と Instance ID(それぞれの物体のID)を予測する
- 同じクラスであっても個々の物体を区別することができる
- 有名なアプローチは YOLACT
- YOLOはリアルタイムにワンステップで物体検出を行うアルゴリズムであると同様に、YOLACTはワンステップでInstance Segmentationを行う
- もう1つの代表的なアルゴリズムは”Mask R-CNN”、2017年に米 Facebook AI Research 所属のKaiming He らが提案(参考)https://arxiv.org/abs/1703.06870
4.RoI Pooling から RoI Align へ
RoI Alignとは・・・
- RoI Alignを導入:
・RoI Pooling の課題:特徴マップ上で固定サイズの特徴ベクトルを切り出す際に、少数を切り捨てるなどの操作をし、情報が粗く離散化されて欠落してしまうため、高精度の推定が難しい
・Alignment(位置合わせ)を重視したRoI(Region of Interest:関心領域)特徴を作成
・候補領域座標の小数点以下の数値の切り捨てを回避 ⇒ 領域のズレを軽減 - 特徴マップをただ間引くのではなく、補完処理によってより多くのピクセルの情報を使う⇒ 推定の精度を上げられた
- 仕組み:
RoIをN×Nのグリッドに分割し、グリッドの各点の値を特徴マップの4ヶ所からサンプリングした値を補間法(billinear interpolation など)で算出→ その結果を最大/平均pooling して固定サイズのRoI特徴ベクトルとする
RoI Alignの手順
- N×Nの特徴マップにしたい場合、N×Nの領域に分割し、その領域1つ1つについて4つの点を打つ
- 1つ1つの点について、周りの4つのピクセルを使い、何らかの補間法で点の値を求める
- 4つの点を1つにまとめる
5.まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント