
- 「軽量化・高速化技術」について学びたいけど理解できるか不安・・・
- 「軽量化・高速化技術」を使うメリットが分からない
- 「軽量化・高速化技術」を体系的に教えて!
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間をしようしたりするため、高速な計算が求められます。このため、データ並列化、モデル並列化、GPUによる高速化技術は不可欠でありますが、興味があってもよく理解できないケースが非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「軽量化・高速化技術」を学習する際のポイントについて解説します。
この記事を参考に「軽量化・高速化技術」が理解できれば、E資格に合格できるはずです。
<<「軽量化・高速化技術」のポイントを今すぐ見たい方はこちら
0.軽量化・高速化技術の概要
- 深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間をしようしたりするため、高速な計算が求められる。
- 複数の計算資源(ワーカー)を使用し、並列的にニューラルネットワークを構成することで、効率の良い学習を行いたい。
- データ並列化、モデル並列化、GPUによる高速技術は不可欠である。
1.モデル並列化
- 親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元する。
- モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。
1.1 モデル並列
- モデルのパラメータ数が多い⇒スピードアップの効率も向上
(jeffrey Dean et al.2016) Large Scale Distributed Deep Networks
1.2 参照論文
- Large Scale Distributed Deep Networks
・Google社が2016年に出した論文
・Tensorflowの前身といわれている。 - 並列コンピューティングを用いることで大規模なネットワークを
高速に学習させる仕組みを提案。 - 主にモデル並列とデータ並列(非同期型)の提案をしている。
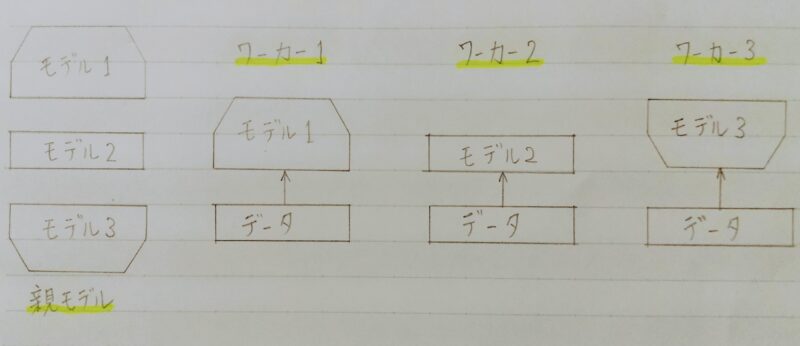
2. データ並列化
- 親モデルを各ワーカーに子モデルとしてコピー
- データを分割し、各ワーカーごとに計算させる
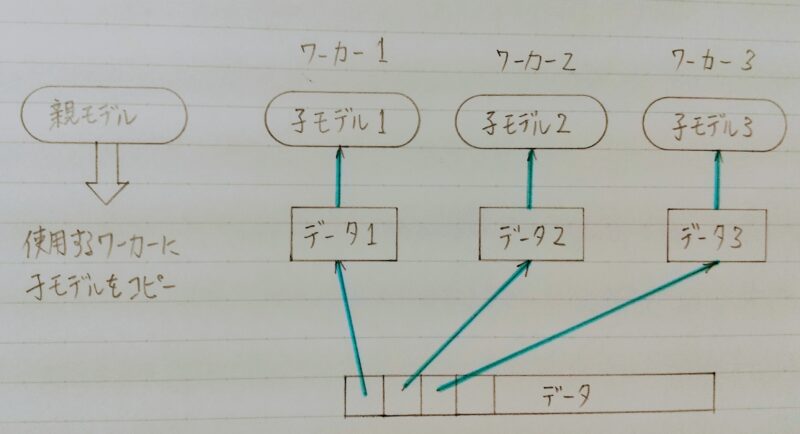
2.1 データ並列化:同期型
- データ並列化は各モデルのパラメータの合わせ方で同期型か非同期型か決まる
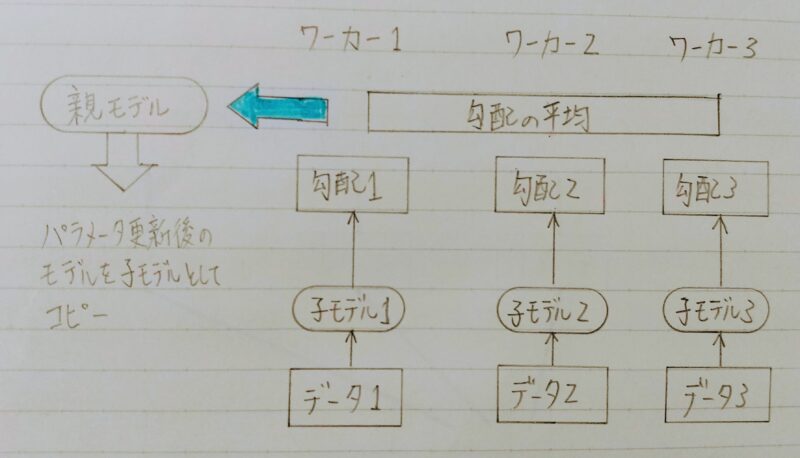
◎同期型のパラメータ更新の流れ
各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する。
2.2 データ並列化:非同期型
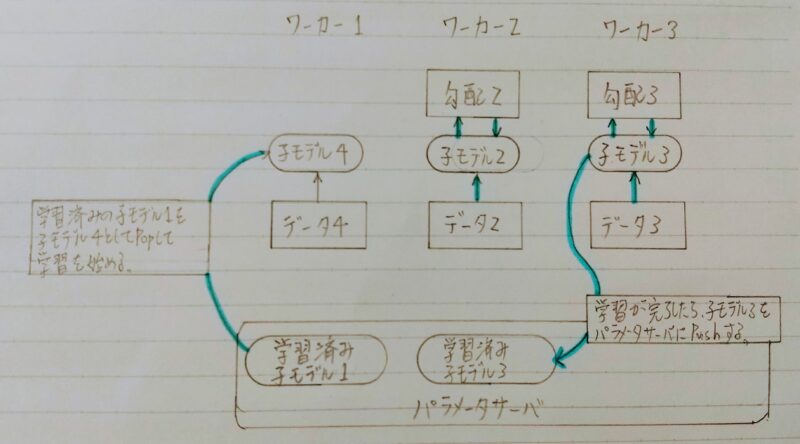
◎非同期型のパラメータ更新の流れ
- 各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。
- 学習が終わった子モデルはパラメータサーバにPushされる。
- 新たに学習を始める時は、パラメータサーバからPopしたモデルに対して学習していく。
2.3 同期型と非同期型の比較
- 処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が速い。
- 非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
→ Stale Gradient Problem - 現在は同期型の方が精度が良いことが多いので、主流になっている。
3.GPU
3.1 GPUによる高速化
- GPGPU(General-purpose on GPU)
・元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称 - CPU
・高性能なコアが少数
・複雑で連続的な処理が得意 - GPU
・比較的低性能なコアが多数
・簡単な並列処理が得意
・ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
3.2 GPGPUの開発環境
- CUDA
・GPU上で並列コンピューティングを行うためのプラットフォーム
・NVIDIA社が開発しているGPUのみで使用可能
・Deep Learning用に提供されているので使いやすい。 - OpenCL
・オープンな並列コンピューティングのプラットフォーム
・NVIDIA社以外の会社(Intel,AMD,ARMなど)のGPUからでも使用可能。
・Deep Learning用の計算に特化しているわけではない。 - Deep Learningフレームネットワーク(Tensorflow,Pytorch)内で実装されているので、使用する際は指定すれば良い。
3.3 モデルの軽量化
- モデルの精度を維持しつつパラメータや演算回数を低減する手法の総称
- 高メモリ負荷 高い演算性能が求められる(通常)
- 低メモリ 低演算性能での利用が必要とされるIoTなど
参照元:山本耕平 橘素子 前野蔵人 ディープラーニングのモデル化技術
https://www.oki.com/jp/otr/2019/n233/pdf/otr233_r11.pdf
4.量子化(Quantization)
4.1 量子化の概要
- 背景と工夫:
ネットワークが大きくなると大量のパラメータが必要となり、学習や推論に多くのメモリと演算処理が必要
「下位の精度に落とす」ことでメモリと演算処理の削減を行う。
例:通常のパラメータの 64 bit 浮動小数点を 32 bit に下げる。 - 用途:
・パラーメータ更新
・パラメータ更新時の「勾配」 - メリットとデメリット
| メリット | デメリット |
|---|---|
| ・省メモリ化 ・計算の高速化 | 精度の低下 |
4.2 メリットとデメリット
ニューロンの重みを浮動小数点の bit 数を少なくし有効桁数を下げることでニューロンのメモリサイズを小さくすることができ、多くのメモリを消費するモデルのメモリ消費量を抑えることができる。
- 倍精度演算(64 bit)と単精度演算(32 bit)は演算性能が大きく違うため、量子化により精度を落とすことにより多くの計算をすることができる。
- 深層学習で用いられる NVIDIA 社製のGPUの性能は下記のようになる。
| CPUタイプ | 単精度(32bit) | 倍精度(64bit) |
|---|---|---|
| NVIDIA*Tesla V100TM | 15.7 TeraFLOPS | 7.8 TeraFLOPS |
| NVIDIA*Tesla P100TM | 9.3 TeraFLOPS | 4.7 TeraFLOPS |
補足)FLOPSとは・・・FLoating-point Operations Per Secondの略語でコンピュータの処理速度をあらわす単位の一つで、1秒間に実行できる浮動小数点数演算の回数。科学技術計算や3次元グラフィックス処理などにおける性能指標として用いられることが多い。
〈参照〉 https://www.nvidia.com/ja-jp/data-center/tesla-v100/
〈参照〉 https://www.nvidia.co.jp/object/tesla-p100-jp.html
先に述べたようにニューロンが表現できる少数の有効桁が小さくなる。
↓
モデルの表現力が低下する
単精度の下限は1.175494×10-38、倍精度の下限は2.225074×10-308になる。
→ 学習した結果ニューロンが1.175494×10-38未満の値になる場合など
重みを表現できなくなる。
↓
ただし、実際の問題では倍精度を単精度にしてもほぼ精度は変わらない。
極端な量子化を考える。表現できる値が 0,1 の 1bit の場合
↓
a=0.1が真値の時、関数 y(x)=ax を近似する場合を考える際、学習によって a が 0.1を得る必要がある。
しかし、量子化によって a が表現できる値が 0,1 のため求められる式は
y(x)=0,y(x)=x
のようになり、誤差の大きな式になってしまう。
↓
4.3 速度の実験結果
32bit と6bit のモデルで検出を行った画像についてそれぞれの検出の時間は下記の表のようになる。
| 32bit | 6bit |
|---|---|
| 0.507s | 0.098s |
| 0.441s | 0.106s |
| 32.269s | 6.113s |
参照元: https://arxiv.org/pdf/1612.06052.pdf
5.蒸留
5.1 蒸留の概要
- 課題
精度の高いモデルはニューロンの規模が大きなモデルになっている。そのため、推論に多くのメモリと演算処理が必要。
- モデルの簡約化
学習済みの精度の高いモデルの知識 → 軽量なモデルへ継承させる。
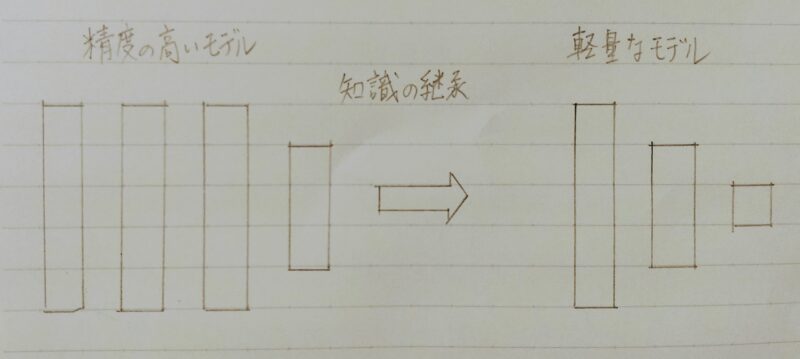
- 蒸留のメリット
・知識の継承により、軽量でありながら複雑なモデルに匹敵する精度のモデルを得ることが期待できる。
・エッジデバイス(携帯電話等)での運用のように計算速度やメモリ容量などが指標となる際に蒸留は有効である。
5.2 仕組み
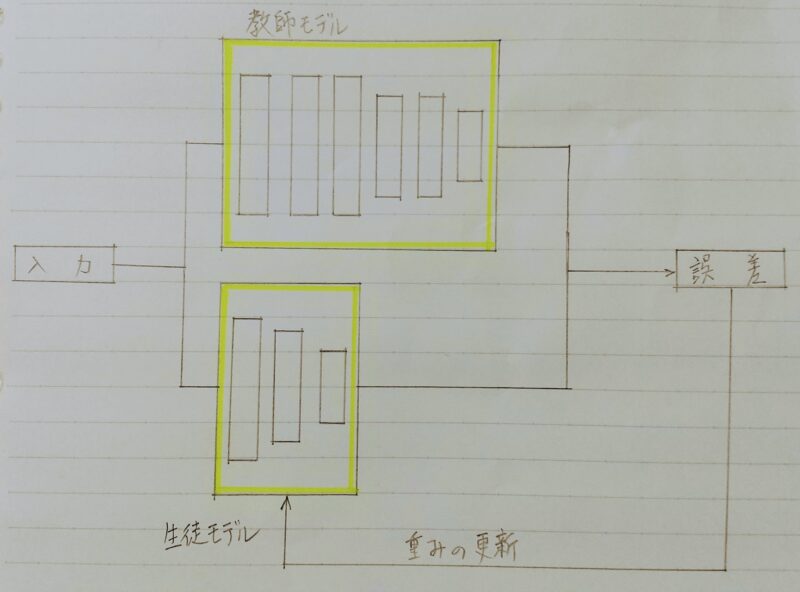
蒸留は教師モデルと生徒モデルの2つで構成される。
- 教師モデル
・予測精度の高い、複雑なモデルやアンサンブルされたモデル - 生徒モデル
・教師モデルをもとに作られる軽量なモデル
・生徒モデル(=小規模モデル)の学習にハードラベルではなく、教師モデル(=大規模モデル)によるソフトラベルを用いる。← 小規模モデルでも大規模モデルの精度が実現できる
・ハードラベル:「0」or「1」
・ソフトラベル:「0~1」 - 引用元
Geoffrey Hinton ,Oriol Vinyals, Jeff Dean (2015)
「Distilling the Knowledge in a Neural Network」,https://arxiv.org/abs/1503.02531
- STEP1:教師モデルの重みを固定し、生徒モデルの重みを更新していく
- STEP2:誤差は教師モデルと生徒モデルのそれぞれの誤差を使い、重みを更新していく
5.3 実験結果
引用論文のグラフはCifar 10 データセットで学習を行ったレイヤー数と精度のグラフになる。
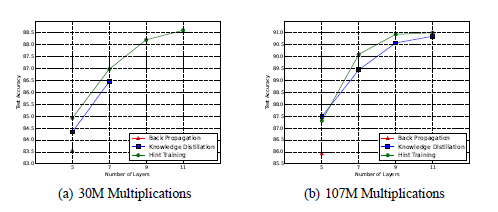
- back propagation:通常の学習
- Knowledge Distillation:先に説明した蒸留手法
- Hint Taraing:引用論文で提案された蒸留手法
グラフから蒸留によって少ない学習回数でより精度の良いモデルを作成することができている。
引用元:Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, Yoshua Bengio(2015)「FITNETS:HINTS FOR THIN DEEP NETS」,https://arxiv.org/pdf/1412.6550.pdf
6.プルーニング(pruning)
6.1 プルーニングの概要
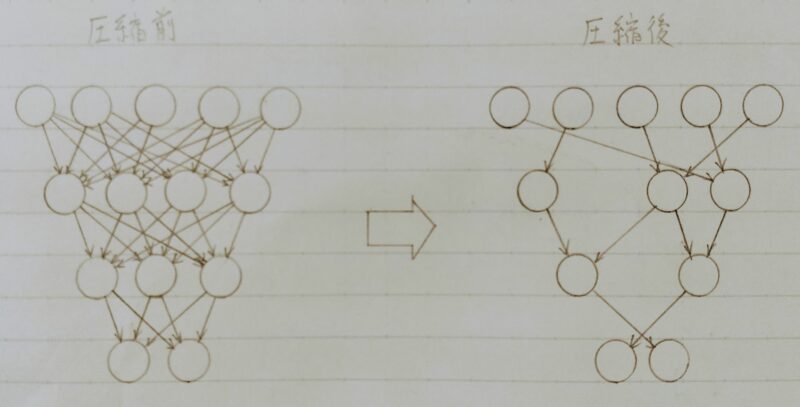
ネットワークが大きくなると大量のパラメータになるが全てのニューロンの計算が精度に寄与しているわけではない。
↓
モデルの精度に寄与が少ないニューロンを削減することでモデルの軽量化、高速化が見込まれる。
pruning:〈直訳〉枝切り
寄与の少ないニューロンの削減を行いモデルの圧縮を行うことで高速に計算を行うことができる。
参照元:Song Han, Jeff Pool, John Tran, William J. Dally(2015)「Learning both Weights and Connections for Efficient Neural Networks」,https://arxiv.org/pdf/1506.02626.pdf
6.2 ニューロンの削減
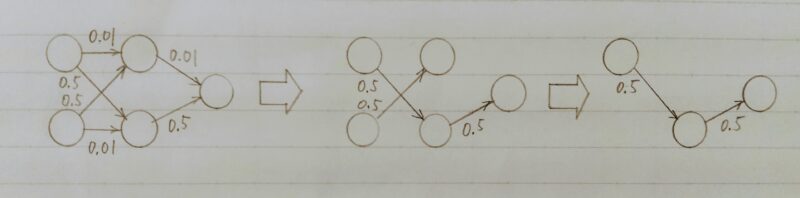
ニューロンの削減の手法は重みが閾値以外の場合ニューロンを削減し、再学習を行う。下記の例は重みが 0.1 以下のニューロンを削減した。
6.3 ニューロンの数と精度の関係
下表は Oxford 102 category ower dataset を CaffeNetで学習したモデルのプルーニングの閾値による各層と全体のニューロンの削減率と精度をまとめたものになる。
- α :閾値のパラメータ
・閾値:各層の標準偏差σ × パラメータ
・閾値を高くするとニューロンは大きく削減できるが精度も減少する。
| α | 全結合層1 | 全結合層2 | 全結合層3 | 全結合層全体 | 精度 (%) |
|---|---|---|---|---|---|
| 0.5 | 49.54 | 47.13 | 57.21 | 48.86 | 91.66 |
| 0.6 | 57.54 | 55.14 | 64.99 | 56.86 | 91.39 |
| 0.8 | 70.96 | 69.04 | 76.44 | 70.42 | 91.16 |
| 1.0 | 80.97 | 79.77 | 83.74 | 80.62 | 91.11 |
| 1.3 | 90.51 | 90.27 | 90.01 | 90.43 | 91.02 |
| 1.5 | 94.16 | 94.28 | 92.45 | 94.18 | 90.69 |
| 1.6 | 95.44 | 95.64 | 93.38 | 95.49 | 90.53 |
| 1.7 | 96.41 | 96.66 | 94.20 | 96.47 | 89.84 |
| 1.8 | 97.17 | 97.43 | 94.88 | 97.23 | 89.94 |
| 1.9 | 97.75 | 98.02 | 95.45 | 97.81 | 89.45 |
| 2.0 | 98.20 | 98.45 | 95.94 | 98.26 | 89.56 |
| 2.2 | 98.80 | 99.03 | 96.74 | 98.85 | 88.97 |
| 2.4 | 99.19 | 99.40 | 97.41 | 99.24 | 87.74 |
| 2.6 | 99.46 | 99.64 | 97.95 | 99.50 | 87.08 |
参照元:佐々木健太、佐々木勇和、鬼塚 真(2015)「ニューラルネットワークの全結合層における パラメータ削減手法の比較」https://db-event.jpn.org/deim2017/papers/62.pdf
7.まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント