
- 「A3C(強化学習)」について学びたいけど理解できるか不安・・・
- 「A3C(強化学習)」を使うメリットが分からない?
- 「A3C(強化学習)」を体系的に教えて!
「A3C」は複数のエージェントが同一の環境で非同期に学習する強化学習法の一つで、DQN(深層Qネットワーク)より短い演算時間で高い性能が得られるモデルすが、よく理解できないケースが非常に多いです。ここでは、「A3C」について要点を解説します。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「A3C」のポイントについて解説します。
この記事を参考に「A3C」のポイントを押さえることができれば、E資格に合格できるはずです。
A3Cとは?
【強化学習の長年の課題】
経験の自己相関が引き起こす学習の不安定化
↓
経験再生(Experience Replay)機構を用いる。
⇒ 経験(バッファに蓄積)をランダムに取り出すことで経験の自己相関を低減
↓
経験再生はオフポリシー手法でしか使えない
↓
オンポリシー手法であり、エージェント(サンプルを集める)を並列化
⇒ 自己相関を低減
- A3C:Asynchronous Advantage Actor-Critic
- 強化学習の学習法の1つ:DeepMindのVolodymyr Mnih(ムニ)のチームが提案
- 特徴:複数のエージェントが同一の環境で非同期に学習すること
3つの”A“とは・・・
- ①Asynchronous ⇒ 複数のエージェントによる非同期な並列学習
- ②Advantage ⇒ 複数ステップ先を考慮して更新する手法
- ③Actor-Critic ⇒ 方策によって行動を選択、状態価値関数に応じて方策を修正
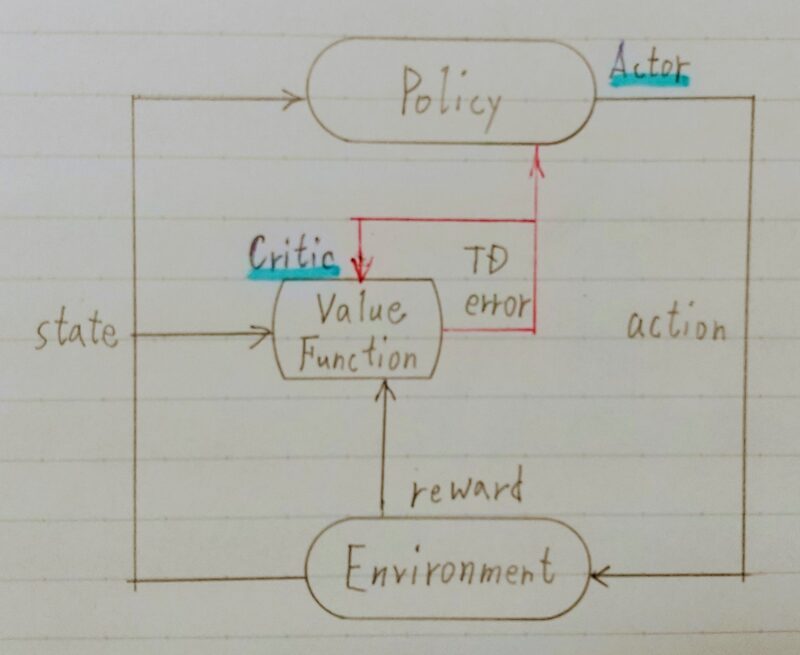
※Actor-Criticとは
行動を決めるActor(行動器)を直接改善しながら、方策を評価するCritic(評価器)を同時に学習させるアプローチ
引用:Sutton,Berto,”Reinforcement Learningーan introduction.”1998
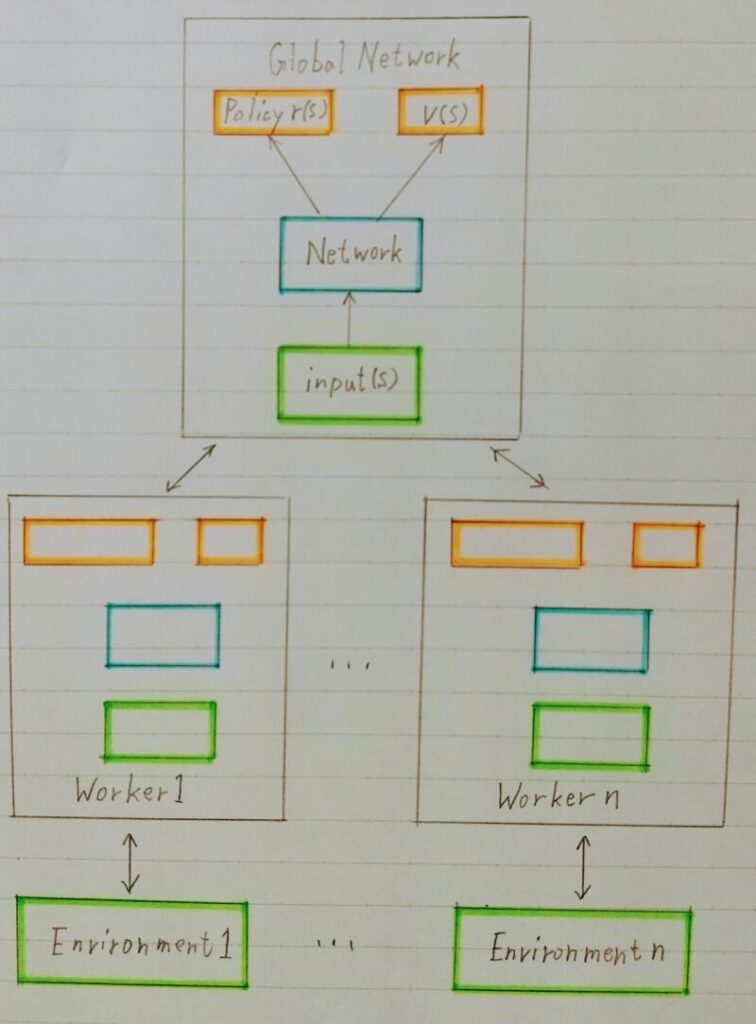
【AC3による非同期(Asynchronous)学習の詳細】
- 複数のエージェントが並列に自律的に、rollout(ゲームプレイ)を実行し、勾配計算を行う
- その勾配情報をもって、好き勝手なタイミングで共有ネットワークを更新する。
- 各エージェントは定期的に自分のネットワーク(local network)の重みをglobal networkの重みと同期する。
参考論文:https://arxiv.org/abs/1602.01783
並列分散エージェントで学習を行うA3Cのメリット
- ①学習が高速化
- ②学習が安定化
AC3のデメリット
- Python言語の特性上、非同期並列処理を行うのが面倒
- パフォーマンスを最大化するためには、大規模なリソースを持つ環境が必要
A2Cについて
- A3Cの後にA2Cという手法が発表された。
A2Cは同期処理を行い、Pythonでも実装しやすい。 - 各エージェントが中央指令部から行動の指示を受けて、一斉に1ステップ進行し、中央指令部は各エージェントから遷移先状態の報告を受けて次の行動を指示する。
- 性能がA3Cに劣らないことが分かったので、その後よく使われるようになった。
分岐型 ActorーCritic ネットワーク
〈一般的なActor-Critic〉方策ネットワークと価値ネットワークを別々に定義し、別々のロス関数(方策勾配ロス/価値ロス)でネットワーク更新
⇔
〈AC3〉
パラメータ共有型のActor-Critic:
1つの分散型のネットワークが、方策と価値の両方を出力し、1つの「トータルロス関数」でネットワーク更新
ロス関数
- ロス関数は3項目で表せる:
- ①アドバンテージ方策勾配
- ②価値関数ロス
- ③方策エントロピー
- Total loss =ー アドバンテージ方策勾配 +α・価値関数ロス ーβ・方策エントロピー
- 係数α:ハイパーパラメータ
- 係数β:ハイパーパラメータ(探索度合いを調整)
アドバンテージ方策勾配項
- 方策勾配法では、θをパラメータに持つ方策nθに従ったときの期待収益ρθが最大になるように、θを勾配法で最適化する。
- 方策勾配定理により、パラメータの更新に用いられる勾配Δθρθは、以下の式で表される。
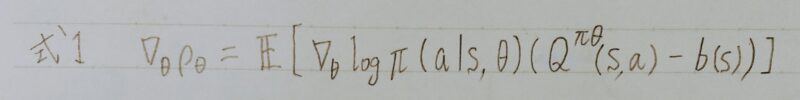
- Actor:方策
- Critic:価値関数
- b(s):価値の「ベースライン」のこと。これを引くことで、推定量の分散が小さくなり学習の安定化が期待できる。
| REINFORCEアルゴリズム | Actor-Critic法 | |
|---|---|---|
| b(s)の取り扱い | b(s)=0として、サンプルされた収益「Qπθ(s,a)」を推定 | パラメトリックな価値関数を用いて収益「Qπθ(s,a)ーb(s)」を推定 |
- (式1)の中の「Qnθ(s,a)ーb(s)」にアドバンテージ関数を設定する
具体的には勾配を推定する際に、
b(s)の推定:価値関数 Vnθ(s)、
Q(s,a)の推定:kステップ先読みした収益(式2)を用いる
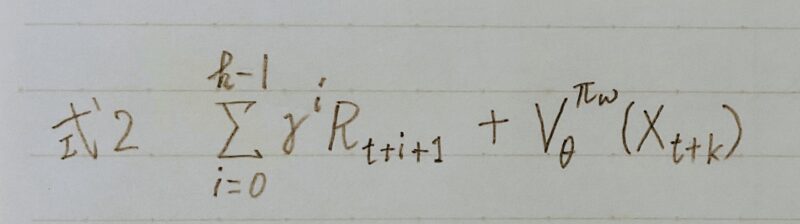
つまり、下式(式3)の期待値が(式1)の勾配と等価
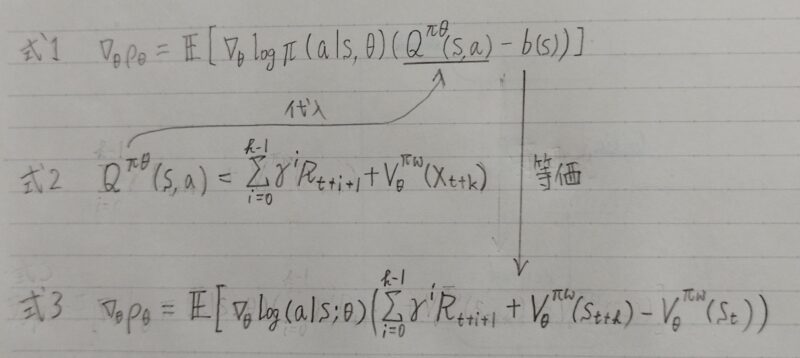
Atari 2600 における性能検証
- Atari 2600において、人間のスコアに対して規格化した深層強化学習の結果で性能を検証
- 結論:より短い訓練期間でGPUなしでも、A3Cのスコアが顕著に高い
- A3C:16 CPUコアのみ使用、GPU使用なし (1~4日間の訓練)
- 他のエージェント:Nvidia K40 GPUを使用(8~10日間の訓練)
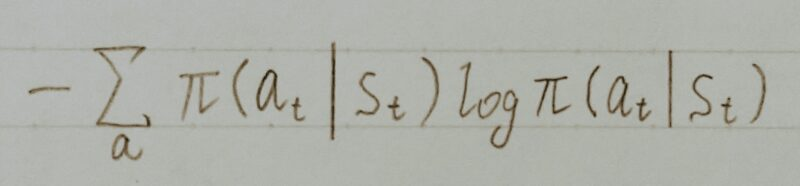
- 方策のランダム性の高い(=エントロピーが大きい)方策にボーナスを与えることで、方策の収束が早すぎて局所解に停滞する事態を防ぐ効果がある。
- 方策エントロピー項の追加は、方策関数の正則化効果が期待できる。
ある状態sの入力について出力される行動の採用確率が下記の①②の場合、
- ① (a1,a2,a3,a4)=[0.25,0.25,0.25,0.25]の場合
- ② (a1,a2,a3,a4)=[0.85,0.05,0.05,0.05]の場合
①の場合の方が方策のエントロピーが大きい状態である。
※A3Cの実装の参考(TensorFlow Blogより)
https://blog.tensorflow.org/2018/07/deep-reinforcement-learning-keras-eager-execution.html
まとめ
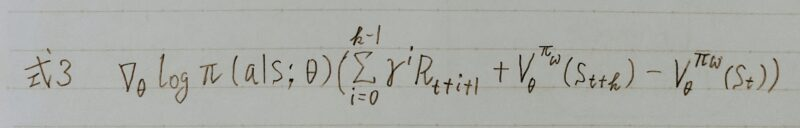
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント