
- 「Transformer」について学びたいけど理解できるか不安・・・
- 「Transformer」についてどこから学んでいいか分からない?
- 「Transformer」を体系的に教えて!
「Transformer」はエンコーダとデコーダをAttentionというモデルのみで結んだネットワーク構造である機械翻訳で用いられますが、難しそうで何から学んだらよいか分からず、勉強のやる気を失うケースは非常に多いです。
私は2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「Transformer」を学習する際のポイントについて解説します。
この記事を参考に「Transformer」が理解できれば、E資格に合格できるはずです。
<<「Transformer」のポイントについて今すぐ見たい方はこちら
EncoderーDecoderモデルの理解と実装
- 入力:系列(Sequence)→ 出力:系列(Sequence)
- EncoderーDecoder モデル
入力系列がEncode(内部状態に変換)され、内部状態からDecode(系列に変換)する - 実応用上も、入力・出力共に系列情報なものは多い
・翻訳(英語→日本語)
・音声認識(波形→テキスト)
・チャットボット(テキスト→テキスト)
- 言語モデルをふたつ連結した形になっている
- RNN(再帰型ニューラルネットワーク)の理解
・RNNの動作原理
・LSTMなどの改良版RNNの理解 - 言語モデルの理解
系列データを読み込むために再帰的に動作するNN(ニューラルネットワーク)
- 出力が再び入力になる
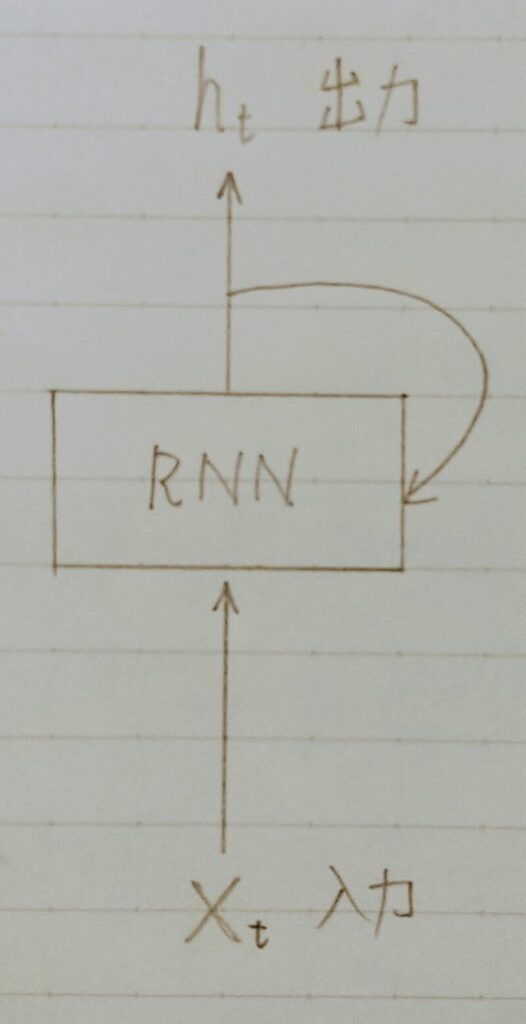
- 時間軸方向に展開できる
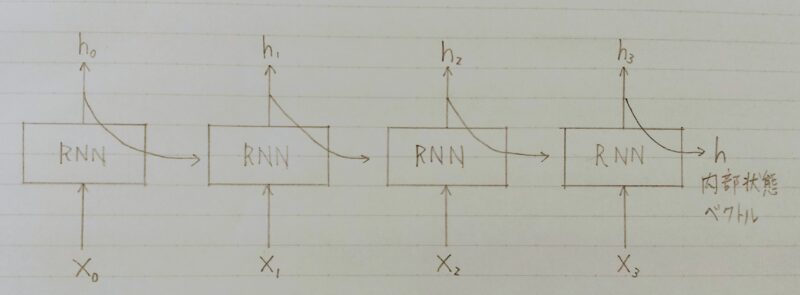
- 系列情報を舐(な)めて内部状態に変換できる
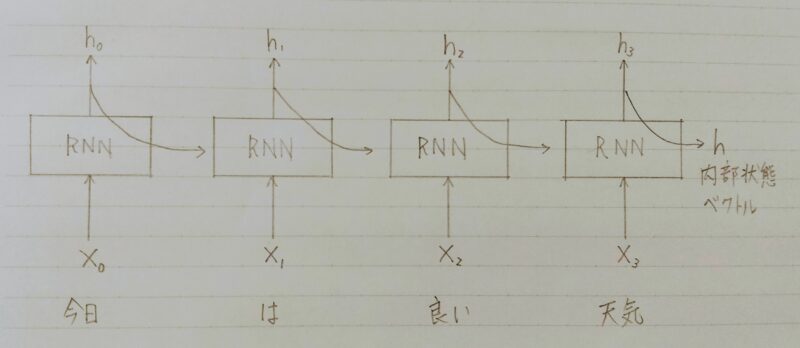
- 単語の並びに確率を与える
- 単語の並びに対して尤度(それがどれだけ起こり得るか)、
すなわち、文章として自然かを確率で評価する。 - 例)
・You say goodbye → 0.092(自然)
・You say good die → 0.00000032(不自然) - 数学的には同時確率を事後確率に分解して表せる
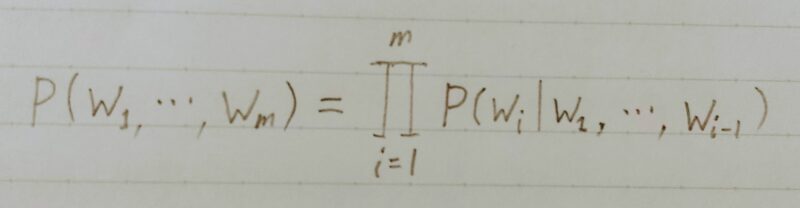
- 時刻t-1までの情報っで、時刻tの事後確率を求めることが目標
→これで同時確率が計算できる
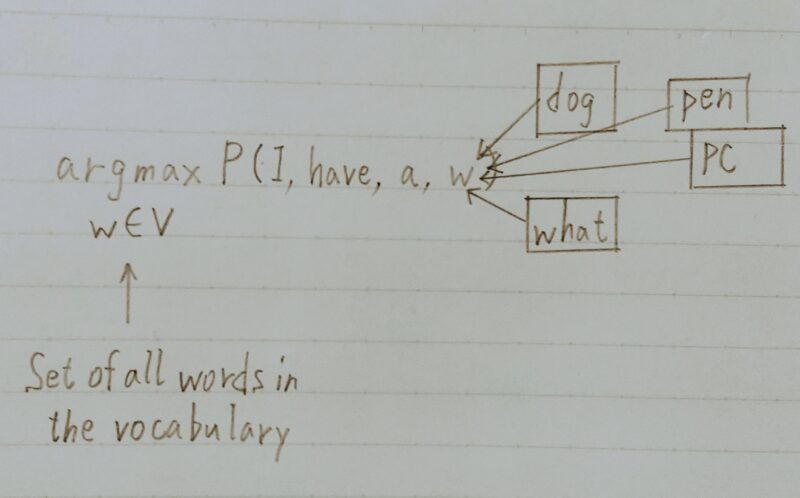
- 各地点で次にどの単語が来れば自然(事後確率最大)かを出力できる。
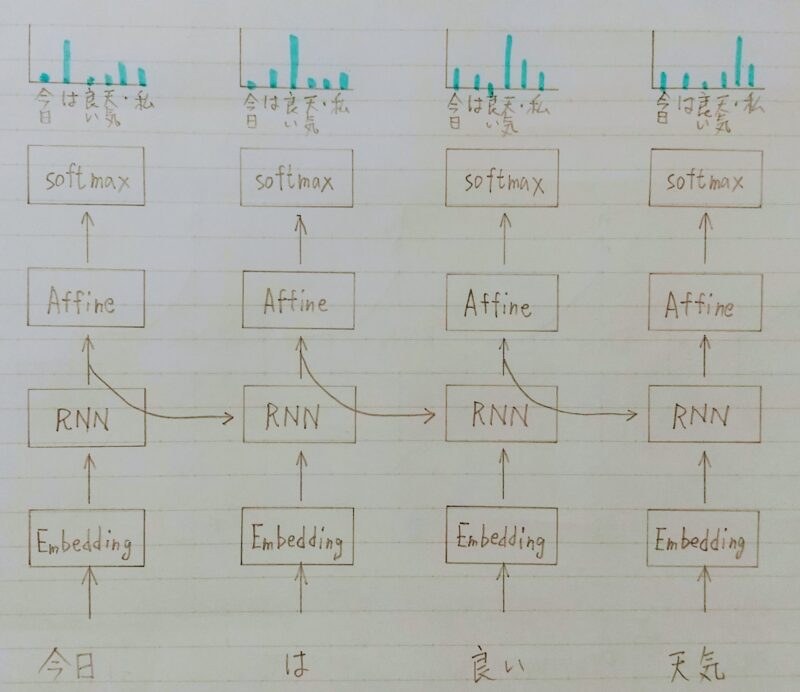
- RNNは系列情報を内部状態に変換する事ができる
- 文章の各単語が現れる際の同時確率は、事後確率で分解できる。
したがって、事後確率を求めることがRNNの目標になる。 - 言語モデルを再現するようにRNNの重みが学習されていれば、
ある時点の次の単語を予測することができる。 - 先頭単語を与えれば文章を生成することも可能
EncoderからDecoderに渡される内部状態ベクトルが鍵
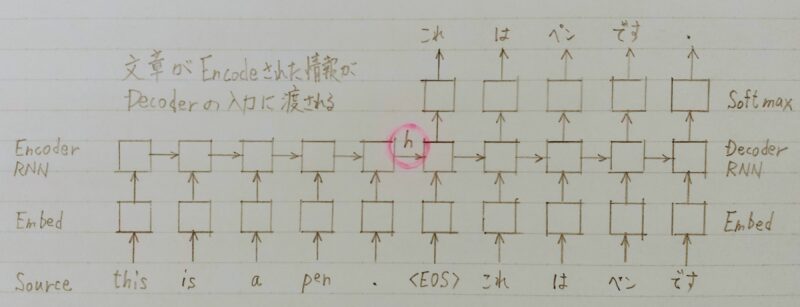
Decoder側の構造は言語モデルRNNとほぼ同じだが
隠れ状態の初期値にEncoder側の内部状態を受け取る。
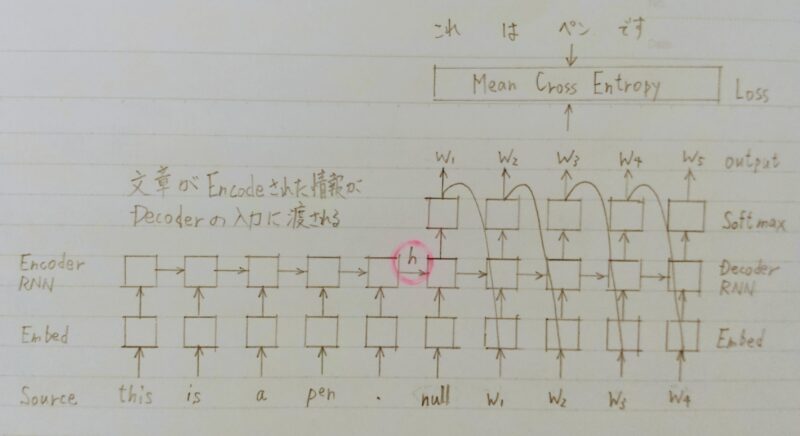
Decoderのoutput側に正解を当てれば教師あり学習が「End to end」で行える。
SelfーAttention(自己注意機構)とは
- 長さに弱い
- 翻訳元の文の内容をひとつのベクトルで表現
→文長が長くなると表現力が足りなくなる - 文長と翻訳精度の関係性
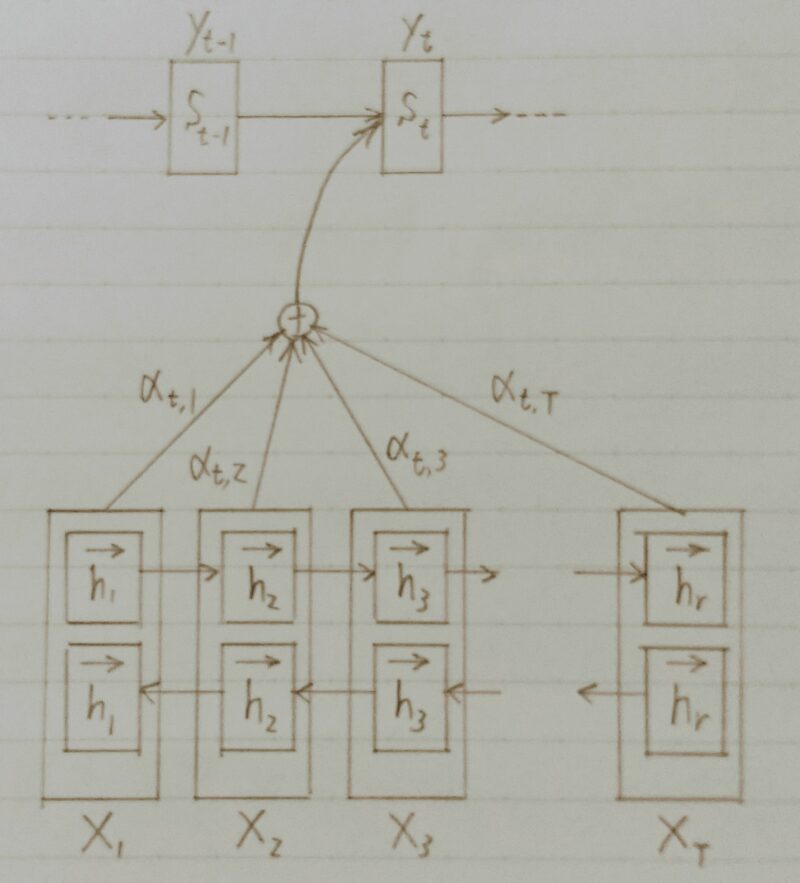
- 翻訳先の各単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用
翻訳元の各単語の隠れ状態の加重平均
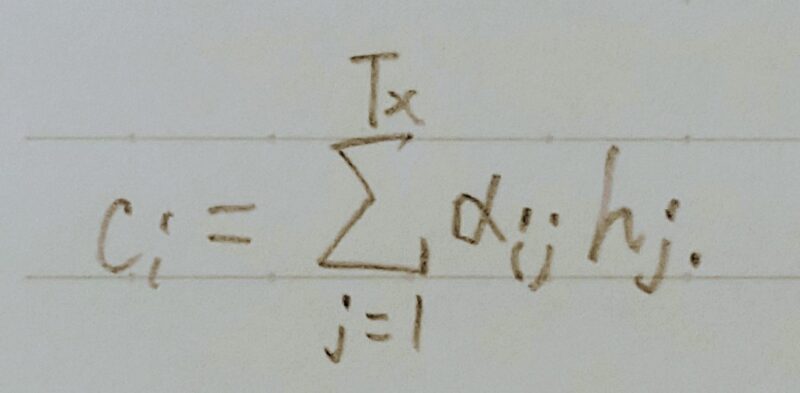
加重平均
重み(全て足すと1)はFFNNで求める
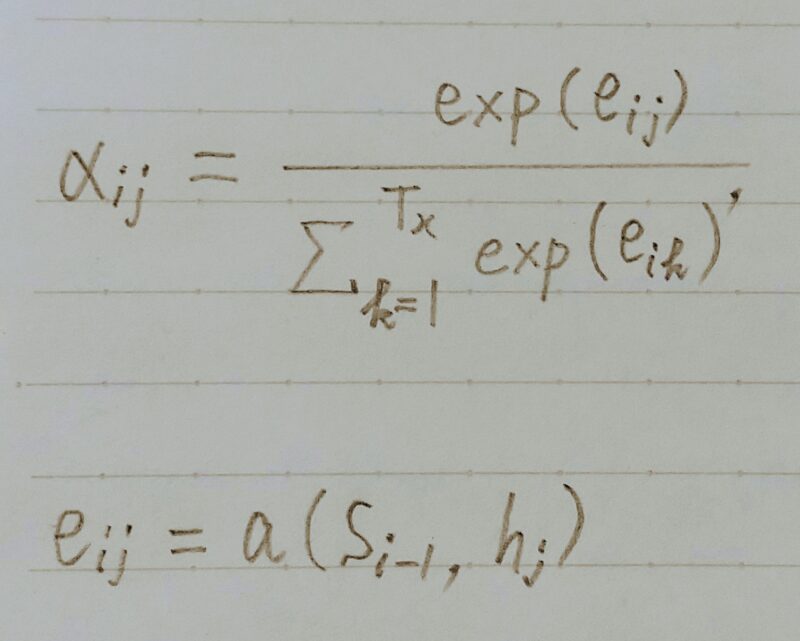
引用元:「Yuta Hayashibe」
- FFNN (FeedForward Neural Network ;順伝播型ニューラルネットワーク)
ネットワークにループする結合を持たず,入力ノード→中間ノード→出力ノードというように単一方向へのみ信号が伝播するもの
・MLP (Multilayer perceptron)とも呼ばれるが,FFNNではオリジナルのパーセプトロンとは異なり,ユニットの入出力関数はステップ関数に限定されない
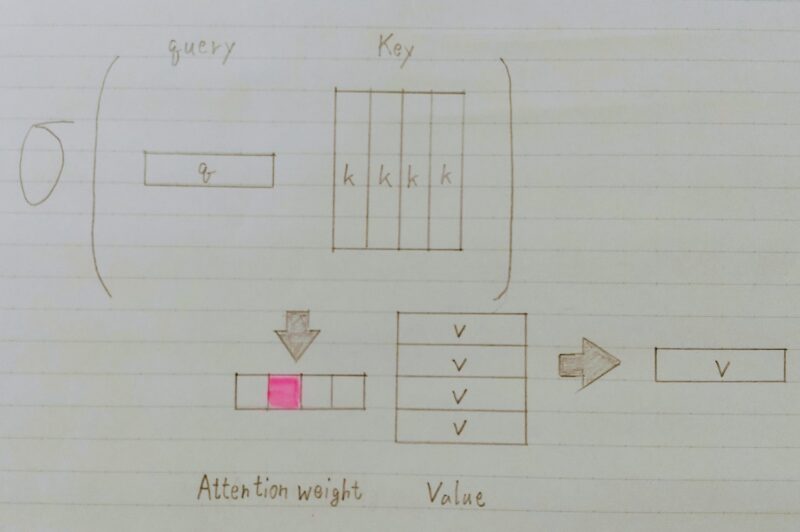
- Attentionは辞書オブジェクト
- Query(検索質問)に一致するKeyを牽引し、対応するValueを取り出す操作⇒ 辞書オブジェクトの機能と同じである。
「Attention」は回帰結合層なの?
「Attention」は回帰結合層ではないよ!
なぜなら、以下の図のような仕組みだからだよ!
- 2017年6月に登場
Transformer(Vaswani et al.,2017)Attention is all you need - RNN(再帰型ニューラルネットワーク)を使わない
・必要なのはAttentionだけ - 当時のSOTAをはるかに少ない計算量で実現
・英仏(3600万文)の学習を8GPUで3.5日で完了
SOTA(State-of-the-Art)とは?
機械学習では、ある特定のタスク&ベンチマークとなるデータセットにおいて論文の内容とその機械学習モデルが「現時点での最先端レベル(=最良/最高)の性能(=正解率などのスコア/精度)」を達成していることを表す。
引用元:@IT
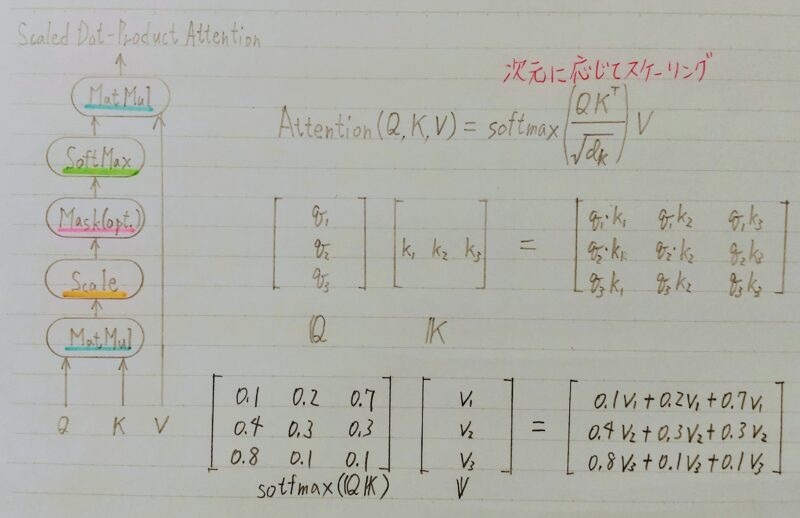
- 注意機構には二種類ある
softmax(QKT)V
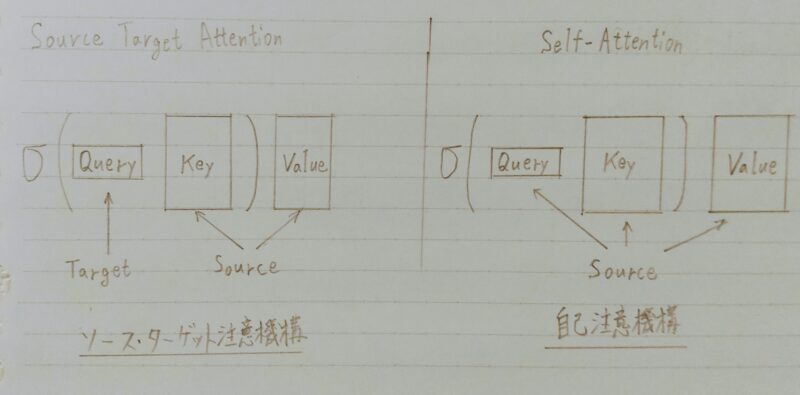
- Self Attention:直訳すると「自己注意」
- Source Target Attention:直訳すると「出典と目標に注意」
| Source Target Attention | Self Attention | |
|---|---|---|
| 分散表現の数 | 2 | 1 |
| 分散表現の 獲得方法 | 1つの分散表現をKey,Value, Queryに分割 | ・1つの分散表現をKey,Valueに分割 ・1つの分散表現をQueryに分割 |
- 入力を全て同じにして学習的に注意箇所を決めていく
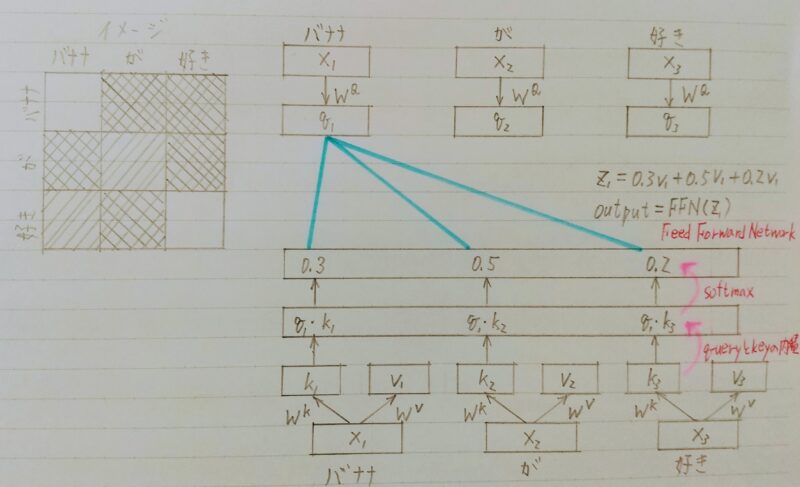
- 自己注意機構により文脈を考慮して各単語をエンコード
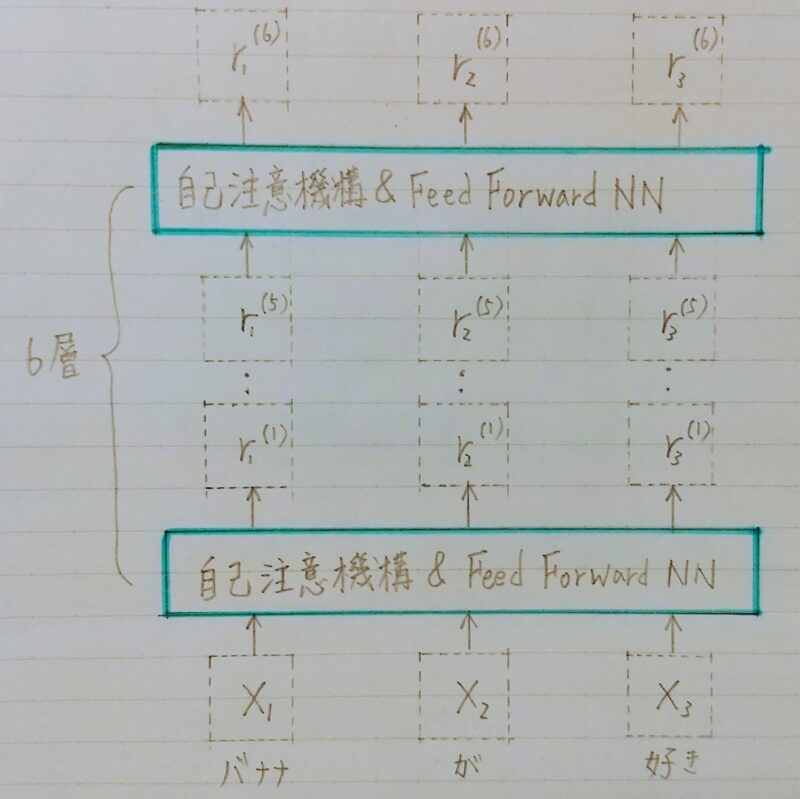
- 位置情報を保持したまま順伝播させる
- 各Attention層の出力を決定
- 2層の全結合層ニューラルネットワーク
- 線形変換→ReLu→線形変換
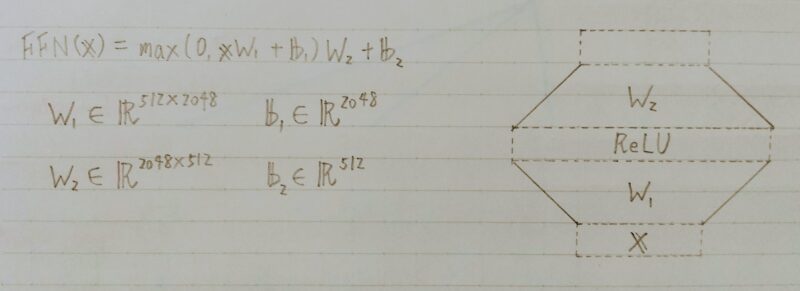
- 全単語に関するAttentionをまとめて計算する
- 重みパラメータの異なる8個のヘッドを使用
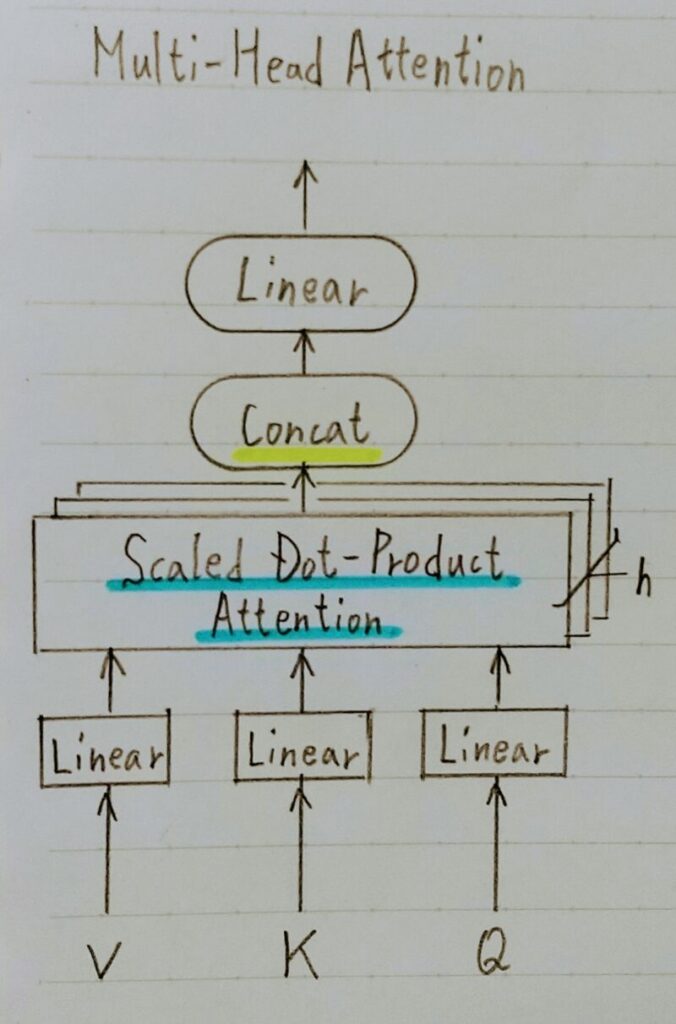
- 8個のScaled DotーProduct Attentionの出力をConcat
- それぞれのヘッドが異なる種類の情報を収集
- 各要素同士がどれほど反応したかを数値化することで可視化できる。
- 入力層と出力層の全てがネットワークで繋がっているため、長い系列文でも依存関係を学習できる。
- 並列計算できるため、回帰結合層よりも計算が速い。
回帰結合層:入力と出力を結合した層
- Encoderと同じく6層
- 各層で2種類の注意機構
- 注意機構の仕組みはEncoderとほぼ同じ
- 自己注意機構
- 生成単語列の情報を収集
直下の層の出力へのアテンション - EncoderーDecoder attention
- 未来の情報を見ないようにマスク
- 生成単語列の情報を収集
- 入力文の情報を収集
Encoderの出力へのアテンション
- Add(Residual Connection)
- 入出力の差分を学習させる
- 実装上は出力に入力をそのまま加算するだけ
- 効果:学習・テストエラーの低減
- Norm(Layer Normalization)
- 各層においてバイアスを除く活性化関数への入力を平均0、分散1に正規化
- 効果:学習の高速化
- RNNを用いないのでモデルに対しどの位置に存在する入力かを知らせる。
入力値がどの順番で入力されるかモデルに示す → 依存関係が起こりやすい位置の情報を用いることができる(性能の向上が期待)
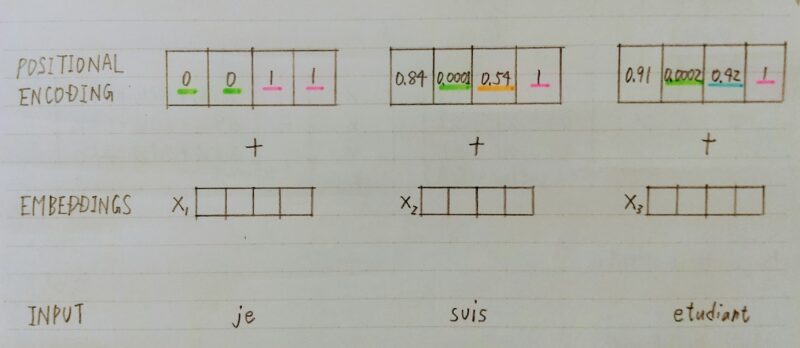
- 単語の位置情報をエンコード
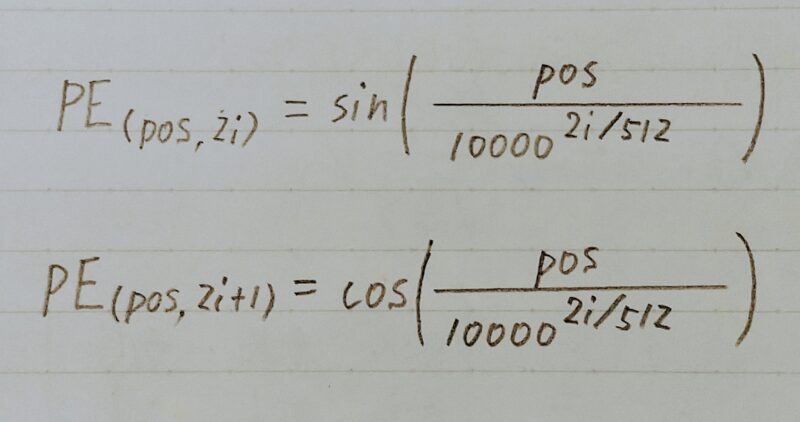
- posの(ソフトな)2進数表現
- 動作イメージ ↓
- Attentionの可視化
- 注意状況を確認すると言語構造を捉えていることが多い
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント