
- 「Semantic-Segmentation」について学びたいけど理解できるか不安・・・
- 「Semantic-Segmentation」の仕組みが分からない?
- 「Semantic-Segmentation」のポイントを教えて!
「Semantic-Segmentation(意味的領域分割)」とはコンピュータビジョンの一分野であり、画像に対して画素(pixel)レベルでクラスを予測する分類タスクです。自動運転や医療画像の分野において重要な技術でありますが、よく理解できないケースが非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこでこの記事では、「Semantic-Segmentation」を学習する際のポイントについて解説します。
この記事を参考にして「Semantic-Segmentation」が理解できれば、E資格に合格できるはずです。
<<「Semantic-Segmentation」のポイントを今すぐ見たい方はこちら
目次
Deconvolution/Transposed-Convolution(逆畳み込み)
著者
Semantic-Segmentationの肝はUpーsamplingをいかに行うかだよ
- 通常のConv.層と同様.kernel size padding stride を指定
- 【処理手順】
1.特徴マップのpixel間隔をstrideだけ空ける
2.特徴マップのまわりに(kernel size – 1) – paddingだけ余白を作る
3.畳み込み演算を行う
右図はkernelsize=3,padding=1,stride=1のDeconv.により3×3の特徴マップが5×5にUpーsamplingされる様子
※「逆畳み込み(Transposed-Convolution)」と呼ばれることも多いが畳み込みの逆演算ではないことに注意 → 当然、poolingで失われた情報が復元されるわけではない。
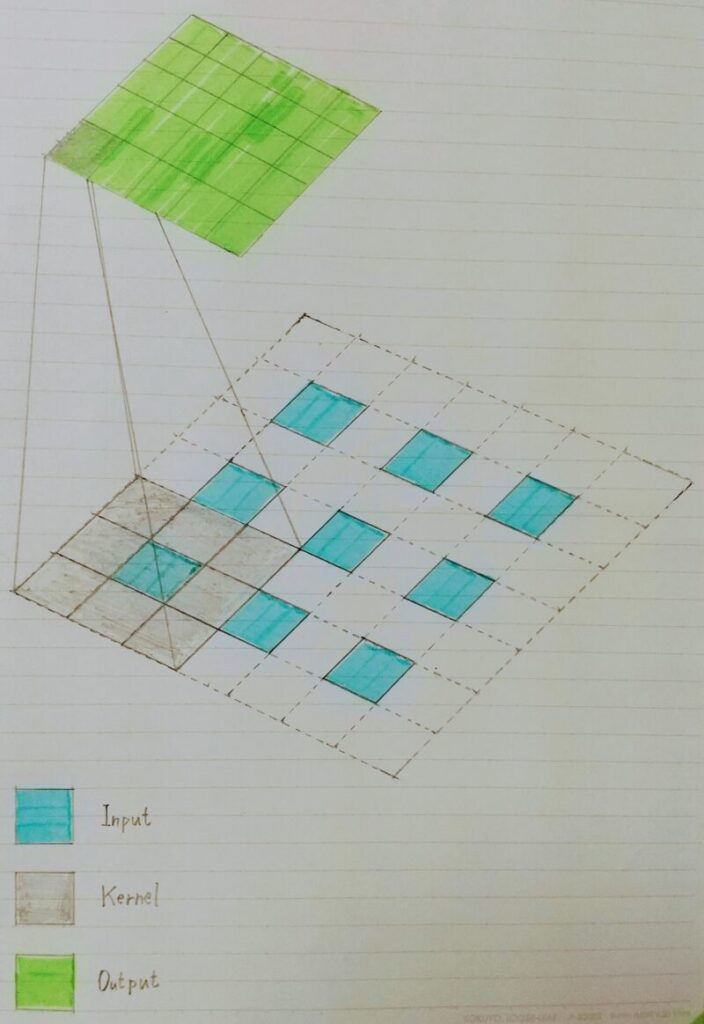
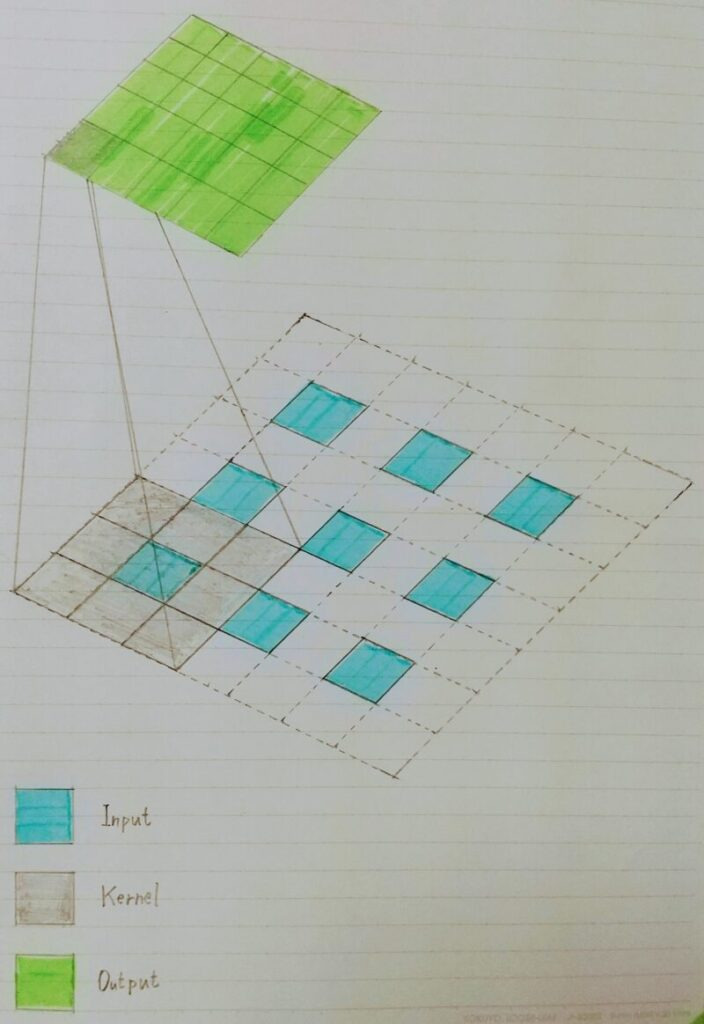
Dilated-Convolution(膨張畳み込み)
- Convolutionの段階で受容野を広げる工夫
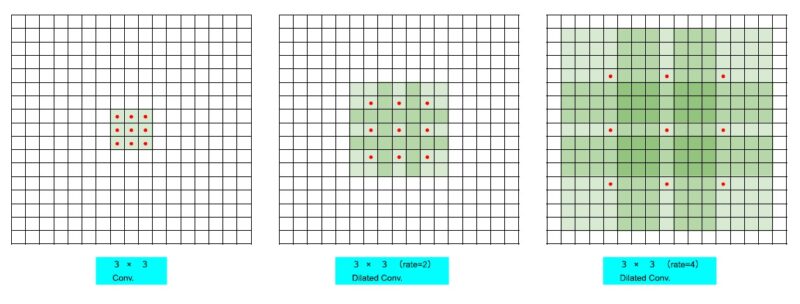
3×3 Conv.のみで同じ受容野を獲得しようとした場合
—–3×3 Conv.–・・・–3×3 Conv.→ 7個のConv.層が必要
代表的なネットワーク構造
「Semantic-Segmentation」の代表的なネットワーク構造として次のものがある。
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント