
- 「FCOS(物体検出)」について学びたいけど理解できるか不安・・・
- 「FCOS(物体検出)」を使うメリットが分からない?
- 「FCOS(物体検出)」を分かりやすく教えて!
「FCOS(Fully Convolutional One-Stage Object Detectionaster)」はone-stageの手法であるため、計算コスト、学習時間を抑えられる物体検出モデルですが、よく理解できないケースが非常に多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格しました。現在、「E資格」にチャレンジ中ですが3回不合格になり、この経験から学習の要点について学ぶ機会がありました。
そこで、この記事では「FCOS」の3つのポイントについて解説します。
この記事を参考に「FCOS」が理解できれば、E資格に合格できるはずです。
概要・序論
- 多くの物体検出モデルは「アンカーボックス」に依存
補足)アンカーボックス=事前に定義した形状の事前に設定した数のバウンディングボックス - FCOS(Fully Convolutional One-Stage Object Detectionaster)は、one-stageの手法である。
- アンカーボックスを使わない。(アンカーボックス・proposalフリー)
中央からの4次元ベクトルとクラスラベルを予測する。
アンカーボックスとは
- 多くの物体検出モデルでは、バウンディングボックスを出力する
- 実はその前に大量のバウンディングボックスの候補を出力していて、その中から”それらしい”ボックスを選んでいる。
- アンカーボックスを使う手法で有名な例
RetinaNet、SSD、YOLOv2、YOLOv3、 Faster R-CNN
アンカーボックスの課題
- ハイパーパラメータの設定に敏感である
- 主なハイパーパラメータとして、アンカーボックスのサイズ・アスペクト比・数がある
- RetinaNetでは、ハイパーパラメータの設定次第で4%の精度が上下することが分かった
- アンカーボックスのサイズやアスペクト比が固定されている
- 向きや角度などによる形の変化が大きい物体に対応できない
- 小型の物体に対応できない
- ポジティブサンプルとネガティブサンプルのバランスが崩れる
- アンカーボックスのほとんどがネガティブサンプルのため、均衡が崩れ学習がうまくいかなくなる
- ネガティブサンプル:検出したい物体が含まれていない領域のこと
- ポジティブサンプル:検出したい物体が含まれている領域のこと
- アンカーボックスのほとんどがネガティブサンプルのため、均衡が崩れ学習がうまくいかなくなる
「oneーstage」採用のメリット
- 「FCOS」では one-stage を採用
oneーstageとはバウンディングボックスの候補領域の選定とクラス判別を一括でおこなうこと - one-stage で済ませることで、計算コスト、学習時間を抑えられる
- 複雑さを抑えることで応用が効く
関連研究
- アンカーベースの手法
- アンカーフリーの手法
特徴マップ上の(i,j)ごとにGraund Truthとの上下左右の距離を回帰する。
※Ground truth:AI モデルの出力の学習やテストに使用される実際のデータを表す。
アンカーフリー
- YOLOv1で画像の中央付近の点からのバウンディングボックスのみ予測する
↓
精度が低くなる
FCOSとYOLOv1
- YOLOv1は中央付近の点のみ
- FCOSは全ての画素(pixel)から四次元ベクトルを予測する.
FCOSの手法
- 全てが畳み込み層で構成される(全結合層が存在しない)ネットワーク
CNN(畳み込むニューラルネットワーク)は、内部に全結合層が存在することによって、固定サイズの画像しか扱うことができなかった。⇒ FCOSは、CNNの全結合層をConvolution層に置き換えることで、入力画像のサイズを固定する制約がなくなった。 - FPN(Feature Pyramid Networks)を使っている
・複数のサイズの特徴マップを生成する手法
・低解像度の特徴は全体の特徴を捉えやすく、意味に強い
・高解像度の特徴は細かい部分に強いが、意味に弱い
・両方の良いところを両立させたのがFPN
- FPNを使うとambiguous sampleの割合が減少
- ambiguous sample とは何か?
・ambiguous sample はFCOSでは問題にならないのか?
| w/FPN | Amb.samples(%) | Amb.samples(diff.)(%) |
|---|---|---|
| 23.16 | 17.84 | |
| ✔ | 7.14 | 3.75 |
- ambiguous sampleが同じクラスだった場合は問題にならないため、右側の列では同じクラスのambiguous sampleを除いたものを表している
- FPNを使わない場合、ambiguous sampleの比率は23.16%、同じクラスのambiguous sampleを除いた方は17.84%ある。しかし、FPNを使うと7.14%、同じクラスのambiguous sampleを除いた方は3.75%にまで減少している
- FPNを使うと重なったオブジェクトは異なる特徴レベル
- 4次元ベクトルのラベルはどうやって計算するのか?
4次元ベクトルのラベルを使ったデータセットがあるわけではなく、バウンディングボックスからラベルのデータセットを加工して使っている
ℓ*= x ー x0(i)
t*= y – y0(i)
r* = x1(i) – x
b* = y1(i) – y
x、y :中央の位置
x0(i) 、 y0(i) :左上の座標
x1(i)、 y1(i) :右下の座標
- CNNではプーリング処理により特徴マップはダウンサンプリングされる。
- FCNの逆畳み込みネットワークでは、逆畳み込みを用いてアップサンプリングを施す。
逆畳み込み(デコンボリューション, deconvolution)とは・・・
元の特徴マップに空白を足して拡大した後に畳み込みフィルタを適応することで、新たな特徴マップを得ることである。アップサンプリング(特徴マップの次元を大きくすること)において用いられる。
CNNの全結合層を置換したConvolution層の画素毎にラベル付けされた教師データを与え学習することで、下記の図のように逆畳み込みを用いてアップサンプリングをして、入力画像の各画素のラベル(物体種別)を推定することができる。引用元:https://arxiv.org/pdf/1505.04366v1.pdfConvolution networkとDeconvolution network のイメージ図
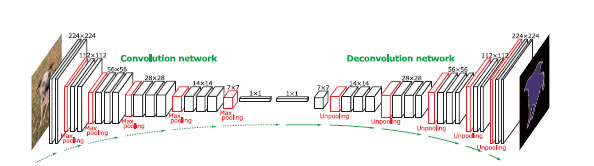
ダウンサンプリングされた特徴マップに対して単純に逆畳み込みをするだけでは粗くなってしまい十分な出力結果が得られない
→ スキップ接続を用いて情報ロスが発生する前の情報をアップサンプリング処理に入力する。
ネットワークの出力について
- クラスラベルの出力
H×W×C の大きさのテンソルが出力つまり、ピクセルごとに各クラスごとのスコアが出力される - 四次元ベクトルの出力
H×W×4ピクセルを中央の点とみなし、全てのピクセルから4次元ベクトルを予測する
4次元ベクトルのポジティブサンプルとネガティブサンプルの分け方
- フィーチャーマップ上のground truth 内に入る全ての点はポジティブサンプルとして扱う
→ 物体の中心から離れた点を中心としたバウンディングボックスが予測されることがある。 - 上記の状況を防ぐため、Center-nessというインデックスを学習に加える
→ 低品質なバウンディングボックスが作成されるのを抑制
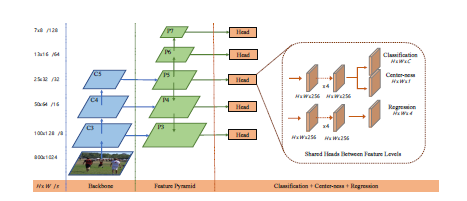
上図の引用論文:FCOS: 完全畳み込み 1 段階物体検出
| ポジティブサンプル | ネガティブサンプル | |
|---|---|---|
| 定義 | 中央の点x,yがラベルのボックスの中に入っていてかつ、 その位置の予測されたクラスとラベルのクラスが一致 | ・左記以外はネガティブサンプル ・c*=0 ← ネガティブサンプル(背景クラス)を表している |
- Center-ness H×W×1
どのくらいx、yの座標が物体中央から離れているかを正規化して表している
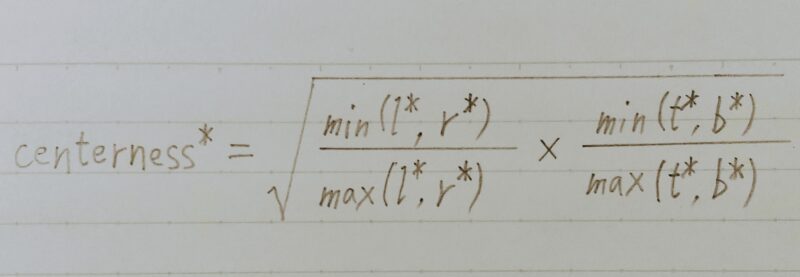
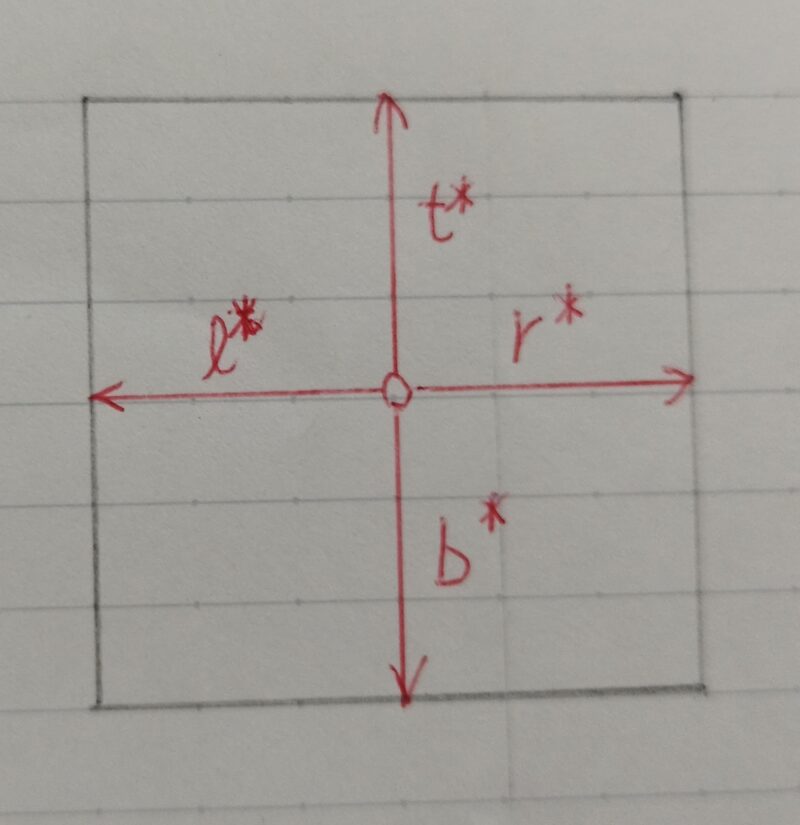
- 左の辺の長さ(上の辺の長さ)と右の辺の長さ(下の辺の長さ)を比べ、小さい方を大きい方で割っている差が小さいほど1に近くなる⇒これで0~1に正規化されたCenterーnessを計算する事ができる
- このラベルと予測されたCenterーnessを、Binary Cross Entropy 関数を使って計算する
- テスト時では分類スコアにCenter-nessをかけてバウンディングボックスの順位付けに使われる
Non-Maximam Suppression
Non-Maximam Suppression:FCOSの唯一の後処理
- ①モデルがスコアを出力する
- ②出力としたバウンディングボックスと他のもののIoUを計算する
- ③IoUの値が閾値より低かった場合、削除する
| 1 | 2 | 3 |
|---|---|---|
| 0.2 | 0.84 | 0.4 |
損失関数
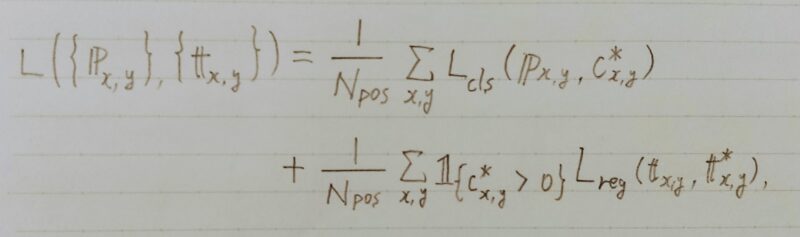
- Lclsはfocal lossという損失関数を使っている
- Lreg は IoU loss を使っている
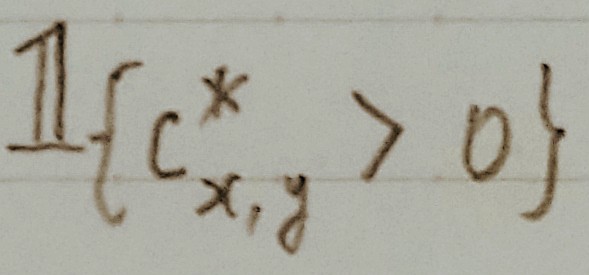
はクラスラベルが背景クラスでなければ1、背景クラスであれば0という意味
- 最後に positive sample の数で割り平均を取る
実験結果
下表はFCOSと他の物体検出手法の性能を比較した結果
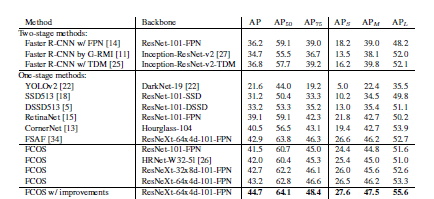
- 上表の引用論文:FCOS: 完全畳み込み 1 段階物体検出
- 上表よりFCOSはYOLOv2やRetinaNetよりAPが高い。
SegNet
FCOS以降に発表されたSegNetというセグメンテーションのアーキテクチャではスキップ接続として符号化器(encoder)の特徴マップの代わりにMax poolingインデックスが用いられる。⇒ SegNet は FCOS に比べて省メモリである。
Max poolingは、順伝播のときmaxのindexを記録し、逆伝播時、記録したmaxのindexを利用して、元位置に戻って、他の位置を0で補完する。
まとめ
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント