- 「AIモデルによる学習方法」を学びたいけど理解できるか不安・・・
- 「AIモデルによる学習方法」についてどこから学んでいいか分からない?
- 「AIモデルによる学習方法」について概略を教えて!
「人工知能(AI:Artificial intelligence)」は既に様々な商品・サービスに組み込まれて利活用が始まっている注目の技術ですが、「AIモデルによる学習方法」を理解していないケースは多いです。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格し、現在、「E資格」取得にチャレンジ中ですが、AIの勉強を始めた頃は「AIモデルによる学習方法」の知識がなく、AIを理解するのに苦労した苦い経験があります。
そこでこの記事では、AIの超初心者の方へ「「AIモデルによる学習方法」について概略を解説します。
この記事を読めば「AIモデルによる学習方法」の概略が学べ、AIの理解向上につながります。
1.AIモデルによる学習
訓練データを用いてAIモデルを学習する。なお、学習する際は、エポック回数(1エポックとは全ての訓練データを学習し終えた段階)、バッチ回数(重みの更新間隔)を適切な値に設定しなければならない。ここで「【深層学習】AIモデルの構築」の例を用いて説明する。
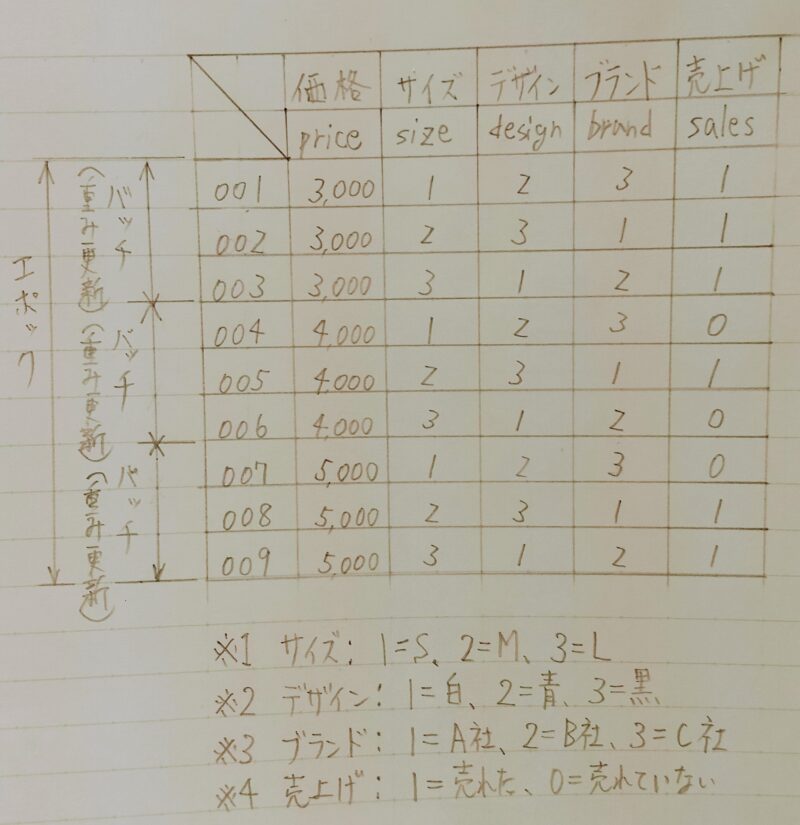
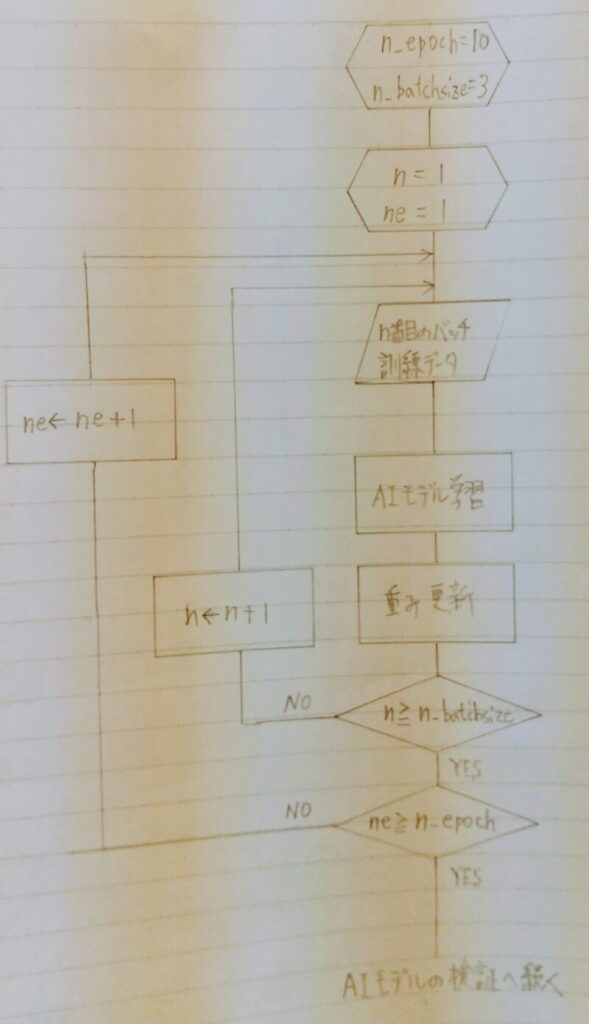
2.学習方法の例
通常AIモデルを勾配降下法で最適化する場合は、データを 1 つ 1 つ用いてパラメータを更新するのではなく「ミニバッチ学習」が使われる。ミニバッチ学習とはいくつかのデータ(バッチサイズ)をまとめて入力し、それぞれの勾配を計算したあと、その勾配の平均値を用いてパラメータの更新を行う方法である。
model.train()
n_epoch = 10 # エポック回数 n_batchsize = 3 # バッチ回数
train_loader = torch.utils.data.DataLoader(train, n_batchsize, shuffle=True) val_loader = torch.utils.data.DataLoader(val, n_batchsize) test_loader = torch.utils.data.DataLoader(test, n_batchsize)
for batch_index, (data, target) in enumerate(train_loader):
data, target = data.to(davice), target.to(device)
optimizer.zero_grad()
output = model(data) # 訓練データより予測値を算出
criterion = nn.BCELoss() # binary_cross_entropy(バイナリ交差エントロピー)
loss = criterion(output, target) # 予測値と目標値の誤差を算出
loss.backward() # 誤差逆伝播
optimizer.step() # 学習率と最適化手法に基づいて重みを更新
・・・
- ※1 バッチサイズ:上記では「3」としているが、慣習として2のn乗の値が使われることが多く、32, 64, 128, 256, 512, 1024, 2048辺りがよく使われる数値
- ※2 エポック数:
①データセットをバッチサイズに従ってN個のサブセットに分ける。
②各サブセットを学習に回す。つまり、N回学習を繰り返す。
①と②の手順により、データセットに含まれるデータは少なくとも1回は学習に用いられる。エポック数とは①、②の手順を何回実行するのかということ。通常、1エポックで十分に学習されることはなく、数~数10エポック回すことが多い。(損失関数の値がほぼ収束するまで)上記では10としている。 - ※3 イテレーション数:データセットに含まれるデータが少なくとも1回は学習に用いられるのに必要な学習回数であり、バッチサイズが決まれば自動的に決まる値。上記の例の場合、9件のデータセットを3件ずつのサブセットに分ける場合はイテレーション数は3 (=9/3)となる。
- ※4 DataLoader: バッチサイズ単位の分割や、学習時のシャッフルなどを行う役目「shuffle=True」の設定によりエポック(=1回学習)が終わるごとに各ミニバッチを構成するデータがランダムに入れ替わる。この設定をする目的は過学習を防ぐこと。
- ※5 enumerate():forループの中でリストやタプルなどのイテラブルオブジェクトの要素と同時にインデックス番号(カウント、順番)を取得できる。
3.まとめ
【AIモデルを学習させる際の注意点】
- エポック回数、バッチ回数を適切な値に設定しなければならない
[affi id=9]
[affi id=10]
コメント