- 「データ分析」について学びたいけど理解できるか不安・・・
- 「データ分析」についてどこから学んでいいか分からない?
- 「データ分析」を体系的に教えて!
「データ分析」は精度の高いAIモデルを構築するために重要なステップであると考えます。
私は過去に基本情報技術者試験(旧:第二種情報処理技術者試験)に合格し、また2年程前に「一般社団法人 日本ディープラーニング協会」が主催の「G検定試験」に合格し、現在、「E資格」取得にチャレンジ中ですが、人工知能の勉強を始めた頃は体系的に理解するのに苦労した苦い経験があります。
そこでこの記事では、人工知能の初心者の方へ「データ分析」について体系的に解説します。
この記事を参考にして「データ分析」が理解できれば、G検定に合格できるはずです。
1.データ分析の基本
1.1 目的の明確化
「データ分析で何をしたいのか」を明確化する。具体的には次のとおりである。
1.2 回帰問題
回帰問題とは連続値を予測することである。具体例は次のとおり。
- 将来の売上げを予測したい。
- 将来の売上げを予測するためには次のデータ分析が必要である。
- 売上げに大きな影響を与える要素は何か?
売上げに大きな影響を与える要素を見付けるためには売上げと相関関係があるかどうか確認する必要がある。故に相関係数を算出する。
次に抽出した要素について、各々に相関関係があるか確認し、もし相関関係があればどちらかの要素を訓練データから除外する。
1.3 分類問題
分類問題とは離散値を予側することである。具体例は次のよおり。
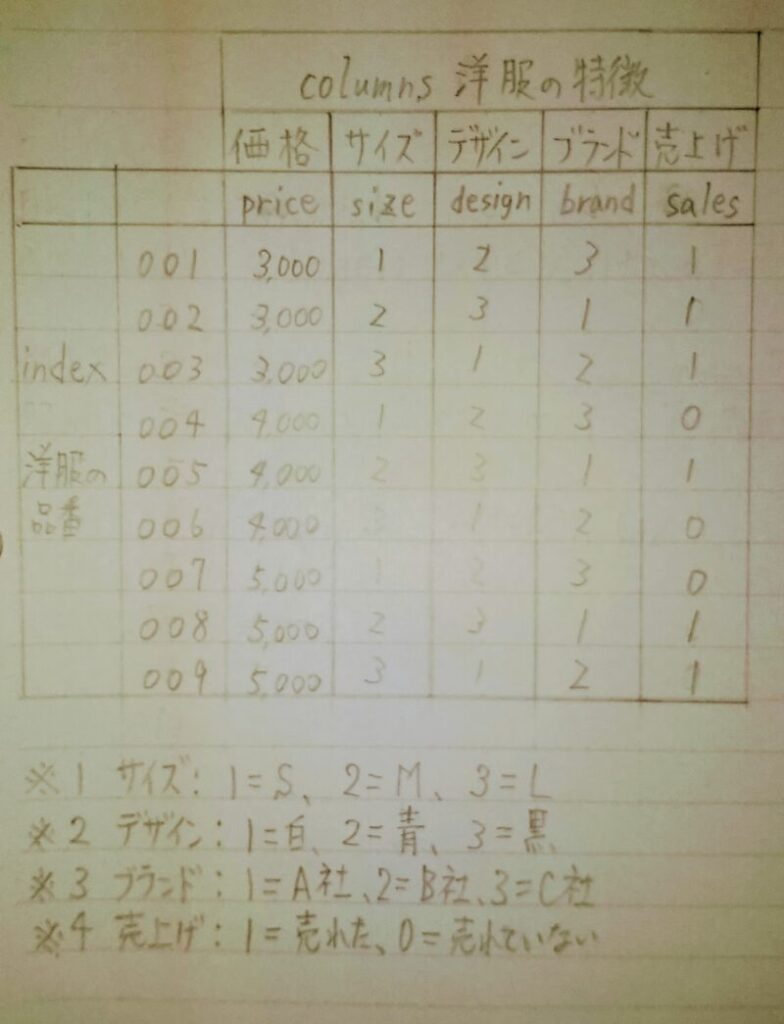
・売れ筋の洋服を予測したい。
洋服が売れる要因には、下表のように価格、サイズ、デザイン、ブランド等がある。 よって、これらの要因と洋服が売れることとの関係があるかどうか確認する必要がある。
1.4 商品分析の手法
商品分析の手法には以下のものがある。
- ①ABC分析
- ②アソシエーション分析
- ③マーケットバスケット分析
- ① ABC分析:売上の高い順に商品を並べ、棒グラフと、高い順に足し上げていった売上高累積構成比を表わす折れ線グラフを作成。商品をランク別にグループ化する。
- ②アソシエーション分析(association analysis):連関分析ともいわれ、データマイニングの分析手法の中核を成すもの。 マーケットバスケット分析は アソシエーション分析の1つである。
※1 データマイニング(Data mining):大量のデータを統計学や人工知能などの分析手法を駆使して、「知識」を見出すための技術。 miningとは「採掘」という意味があり、言い換えると情報(データ)から有益なものを採掘すること。
2.データセットの理解
扱うデータセットがどういった内容のものか理解する必要がある。そこでデータセットを可視化する方法について解説する。
2.1 データセットの表示
データセットの内容を表示する。 例: inport pandas as pd df = pd.read_csv(‘○○/○○/○○.csv’)
print(df.head()) print(df.tail()) ※1 pandas : pandas.DataFrame、pandas.Series ※2 head():datasetの先頭(最初)の5行を表示する。pandas.DataFrame、pandas.Seriesのデータを確認するときに便利なメソッドである。 ※3 tail(): datasetの末尾(最後)の5行を表示する。 pandas.DataFrame、pandas.Seriesのデータを確認するときに便利なメソッドである。
2.2 データ全体の行数や列数を表示
データ全体の行数や列数を表示する。
例: df.shape[0] #全行数を表示
df.shape[1] #全列数を表示 df.info() #全行数、全列数等を表示 #1 shape[] :pandas.DataFrameのデータの行数・列数を表示できる。
#2 info() :pandas.DataFrameのデータの行数・列数や全体のメモリ使用量、各列のデータ型や欠損値ではない要素の数などの情報を表示できる。
3.データの可視化
扱うデータを解析するために図表に可視化する。 グラフを描画することでデータの特性を可視化する。グラフには以下のものがある。
- ①棒グラフ
- ②散布図
- ③箱ひげ図
- ④ヒストグラム
- ⑤折れ線グラフ
- ⑥ヒートマップ:2次元データ(行列)の個々の値を色や濃淡として表現した可視化グラフの一種である。隣にフラクタル図や樹形図を付け、変数によるヒエラルキー値を表現するため同様に色分ける事がある。
- ⑦二次関数
3.1 棒グラフの描画
棒グラフを描画する。
例: %matplotlib inline
import matplotlib.pyplot as plt
inport pandas as pd
df = pd.read_csv(‘○○/○○/○○.csv’)
plt.figure(figsize=(〇,〇)) #棒グラフのサイズを決定 plt.bar(df.columns, df.columns.sum()) #columnsを横軸、各columnsの合計を縦軸とした棒グラフ plt.xlabel(“columns”) #x軸のラベルをcolumns plt.ylabel(“columns sum”) #y軸のラベルをcolumns sum plt.show()
※1 matplotlib :データをグラフや画像データとして表示することができるグラフ描画のためのライブラリ。Pandasでもデータの可視化は可能であるがmatplotlib を利用することで更に複雑な表示が可能。
※2 plt.bar( 横軸の値, 縦軸の値 ):棒グラフを描画するメソッド
3.2 散布図の描画
散布図を作成する。 例: %matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(df[columns], df[index])
plt.show()
※1 scatter:散布図を描くにはMatplotlibに用意されたplt.scatterというメソッドを使用する。 df[columns]はグラフに出力するx軸のデータ、 df[index]はグラフに出力するy軸のデータ。
3.3 箱ひげ図の描画
箱ひげ図を作成する。 例: import seaborn as sns
sns.boxplot(df[columns])
plt.show()
※1 boxplot:seabornに用意されている箱ひげ図を描くためのメソッド。Matplotlibに用意されているplt.boxplotより便利。
3.4 ヒストグラムの描画
ヒストグラムを描画する。 例: %matplotlib inline
import matplotlib.pyplot as plt
plt.hist(df[columns], bins=50)
plt.show()
※1 hist():matplotlibに用意されているヒストグラムを描くためのメソッド
3.5 折れ線グラフの描画
折れ線グラフを描画する。 例: %matplotlib inline
import matplotlib.pyplot as plt
plt.plot(df[columns])
plt.show()
※1 plot():matplotlibに用意されている折れ線グラフを描くためのメソッド
3.6 ヒートマップの描画
ヒートマップを描画する。 例: import seaborn as sns
corr_train = train_data.corr() sns.heatmap(corr_train) plt.show()
※1 heatmap(): seaborn に用意されているヒートマップを描くためのメソッド
3.7 二次関数の描画
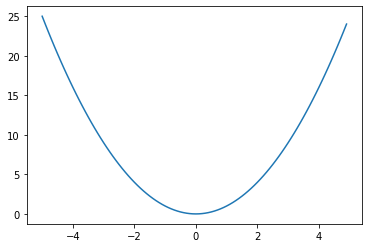
二次関数 f(x)=x2のグラフを描画する。
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5, 5, 0.1)
y = x**2
plt.plot(x, y)
plt.show()
※2 matplotlib: データをグラフや画像データとして表示することができるグラフ描画のためのライブラリ。Pandasでもデータの可視化は可能であるが、matplotlibを利用する事で更に複雑な表示が可能。
最後まで読んで頂きありがとうございます。
皆様のキャリアアップを応援しています!!
コメント